۱- تعریف و کاربردها
تشخیص گوینده ((speaker recognition)) عبارت است از فرایند تشخیص خودکار هویت شخص صحبتکننده بر اساس اطلاعات یکتای موجود در موج صوتی صحبت او.
این فنآوری امکان تشخیص هویت شخص گوینده و در نتیجه امکان کنترل دسترسی او در هنگام استفاده از خدماتی همانند شمارهگیری صوتی، بانکداری تلفنی، خرید تلفنی، خدمات دسترسی به پایگاه دادهها، خدمات اطلاعاتی، پست الکترونیکی صوتی، کنترل امنیتی برای ورود به قلمروهای اطلاعاتی محرمانه و دسترسی از راه دور به کامپیوترها را فراهم میآورد. علاوه بر موارد فوق که عموماً با کامپیوتر و کاربران آن سروکار دارند این فنآوری در مسائل قضایی نیز کاربردهای خاص خود را دارد.
۲- انواع سیستمهای تشخیص گوینده
سیستمهای تشخیص گوینده از لحاظ روش استفاده، همانند آنچه برای کلیهی سیستمهای امنیتی مبتنی بر زیستسنجی در فصل پیش بیان شد، عموماً در دو دستهی سیستمهای تأیید هویت گوینده ((speaker verification systems)) و سیستمهای بازشناسی هویت گوینده ((speaker identification systems)) قرار میگیرند.
در یک سیستم تأیید هویت گوینده، شخص عموماً با انتخاب یا وارد کردن نام یکی از کاربران خاص سیستم ادعا میکند که او همان کاربر ثبتشدهی سیستم است. در این حالت سیستم وظیفه دارد ویژگیهای صوتی شخص مدعی را با ویژگیهای صوتی ذخیره شدهی کاربر ثبت شدهی مورد ادعا مقایسه نموده و با استفاده از نتیجهی به دست آمده ادعای شخص را بپذیرد یا رد کند.
در یک سیستم بازشناسی هویت گوینده، شخص صحبت کننده ادعای هویت یک کاربر خاص ثبت شده را نمینماید و این سیستم است که وظیفه دارد که او را در میان کاربران ثبت شدهی سیستم بازشناسی نماید و یا تشخیص دهد که ویژگیهای صوتی او با هیچ یک از کاربران ثبت شده همخوانی ندارد.
به نظر میرسد در آینده کاربردهای سیستمهای نوع دوم در سیستمهای بزرگ چند کاربره چشمگیرتر از کاربردهای سیستم نوع اول باشد، ((این عقیده، نظر منبع شمارهی ۲ است [ر.ک. صفحهی 19 آن منبع])) هر چند که در اساس این دو سیستم تفاوتهای چشمگیری مشاهده نمیشود.
شکل شمارهی 1 ساختار اساسی این دو نوع سیستم تشخیص گوینده را به تصویر میکشد.
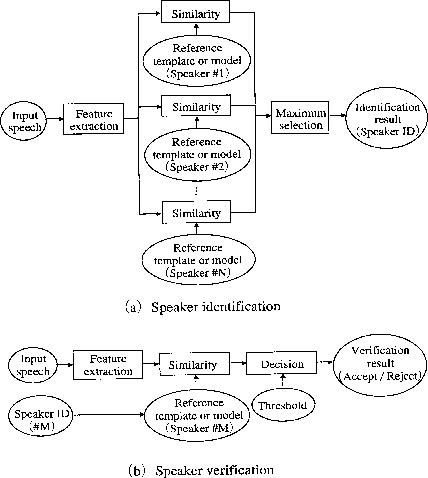
شکل شمارهی 1- ساختار اساسی سیستمهای بازشناسی هویت و تأیید هویت گوینده (منبع شمارهی 1)
سیستمهای تشخیص گوینده از دیدگاه دیگری به دو دستهی سیستمهای تشخیص گویندهی وابسته به متن ((text-dependent speaker recognition systems)) و سیستمهای تشخیص گویندهی مستقل از متن ((text-independent speaker recognition systems)) تقسیم میشوند. روش اول نیازمند آن است که گوینده کلمات کلیدی یا جملههای ثابتی را چه در مرحلهی یادگیری و چه در آزمونهای تشخیصی بیان کند، در حالی که دومی وابسته به جمله یا کلمهی خاصی نیست.
هر دو روش دارای یک مشکل هستند و آن این است که میتوان از صدای ضبط شدهی کاربران ثبتشده برای ورود به سیستم استفاده نمود و به آسانی سیستم را فریب داد. برای غلبه بر این مشکل روشهایی وجود دارند مثلاً میتوان از یک مجموعهی کوچک از کلمات مانند ارقام به عنوان کلمات کلیدی استفاده نمود و در هر زمان به صورت تصادفی از کاربر خواست که یک دنباله از آنها را بیان کند. حتی این روش هم کاملاً قابل اطمینان نیست چرا که میتواند با استفاده از تجهیزات پیشرفتهی الکترونیکی که توانایی تولید دنبالههای عبارات را دارند فریب داده شود. سیستمهای دارای ساختار اخیر به سیستمهای تشخیص گویندهی اعلان متن ((text-prompted speaker recognition systems)) (متن تولید شده توسط ماشین) معروفند.
۳- روشهای پیادهسازی
تقریباً در تمامی سیستمهای تشخیص هویت با استفاده از فرایندی که به تشخیص الگو ((pattern recognition)) شهرت دارد شباهت هر زوج نمونه نمرهگذاری میشود. استفاده از این روش نیازمند وجود دستهای از خصایص منحصر به فرد و قابل مقایسه که از ویژگی انتخاب شده به عنوان ورودی سیستم استخراج شده میباشد.
ویژگیهای فیزیکی افراد نظیر ساختار اندامهای صوتی، اندازهی چالهی بینی و ویژگیهای تارهای صوتی منحصر به فرد بوده و از طریق الگوریتمهای پردازش سیگنال به صورت پارامترهای خصیصهای ((feature parameters)) یا مجموعهی خصایص ((feature set)) قابل استخراج میباشند. این حقیقت پایهی روشهای پیادهسازی سیستمهای تشخیص صحبت میباشند.
مهمترین گلوگاه سیستمهای تشخیص گوینده (و به تبع هم خانواده بودن مهمترین گلوگاه سیستمهای تشخیص صحبت) نحوهی عملکرد آنها در مکانهای دارای شرایط متفاوت با شرایط آزمایشگاهی که از ویژگیهای عمدهی آنها میتوان به حضور نویز در سیستم اشاره کرد میباشد. برای غلبه بر این مشکل از روشهای هنجارسازی ((normalization)) استفاده میگردد که این روشها نیز انواع مختلفی دارند و در سیستمهای تجاری موجود، اغلب نمود پیدا میکنند.
۴- منابع فصل
1) Sadaoki Furui, NTT Human Interface Laboratories, Tokyo, Japan, Speaker Recognition, from clsu.cs.ogj.edu
2) Martin Cultenbruner, Audiotry User Interfaces for Desktop, Mobile and Embeded Applications
3) Richard Duncan, Mississipi State University, A Description And Comparison Of The Feature Sets Used In Speech Processing