۱- مقدمه
همچنان که پیش از این گفته شد سیستمهای تشخیص گوینده ((Speaker Verification)) در حالت کلی به دو نوع سیستمهای تأیید هویت گوینده و سیستمهای بازشناسی گوینده ((Speaker Identification)) تقسیم میشوند. تفاوت این دو سیستم در نحوهی پذیرش ورودی است: در سیستمهای نوع اول گوینده با ارائهی یک شناسه ادعای هویت یک کاربر خاص را مینماید حال آن که در سیستمهای نوع دوم گوینده فقط عبارت عبور خود را بیان میکند و سیستم او را از بین تمامی کاربران خود تشخیص میدهد.
در فصل قبل در مورد ساختار الگوهای مورد بحث صحبت کردیم و متوجه شدیم که عمل مدلسازی سیگنال یا استخراج خصیصهها ((feature extraction)) با حذف ویژگیهای بدون استفادهی سیگنال صحبت و حفظ ویژگیهای قابل استفاده برای بازشناسی عبارات خاص الگوهایی را با ویژگیهای انتخاب شده در اختیار ما قرار میدهد.
ساختارهایی که برای هر دو نوع سیستم ارائه شد هر دو دارای یک مرحله برای تشخیص میزان شباهت الگوهای متعلق به گویندهی حاضر با گویندهی مورد ادعا (نوع اول) یا همهی گویندگان است که با استفاده از آن معیاری برای تصمیم گیری در اختیار ما قرار داده میشود.
همچنان که برای تشخیص الگو الگوریتمهای متعدد و روشهای گوناگون وجود دارد الگوریتمهای گوناگونی نیز برای یافتن میزان شباهت میان الگوها وجود دارد که انتخاب هر کدام از آنها بستگی به ساختار سیستم مقصد دارد.
انتخاب یک روش به ویژگیهای سیستم هدف بستگی دارد. بعضی از روشهای موجود تنها میتوانند فقط برای سیستمهای وابسته به متن ((text-dependent)) یا فقط برای سیستمهای مستقل از متن ((text-independent)) مورد استفاده قرار گیرند و بعضی میتوانند برای هر دو نوع مورد استفاده قرار گیرند.
بحث این فصل که سه روش عمدهی یافتن میزان شباهت الگوها را به صورت کلی مورد بحث قرار خواهد داد عملاً پیشزمینههای نظری لازم برای طراحی سیستم هدف را کامل میکند.
۲- روشهای مبتنی بر چشمپوشی زمانی پویا ((Dynamic Time Wrapping [DTW]))
این روش کلاسیک برای تشخیص خودکار گوینده در حالت وابسته به متن بر اساس یکسانسازی الگوها با استفاده از الگوهای طیفی ((spectral templates)) یا روش طیفنگاره ((spectogram)) استوار است. در حالت کلی سیگنال صحبت به صورت یک دنباله از بردارهای خصیصه ((feature vector)) که رفتار سیگنال صحبت را برای یک گویندهی خاص مشخص میکند نمایش داده میشود. یک الگو میتواند نمایشگر یک عبارت چند کلمهای، یک کلمهی منفرد، یک هجا یا یک صدای ساده باشد.
در روشهای یکسانسازی الگوها مقایسهای بین الگوی عبارت ورودی و الگوی مرجع برای تشخیص هویت گوینده انجام میگیرد. یک جزء مهم در این روشها بهنجارسازی تغییرات زمانی هر آزمون تا آزمون بعدی میباشد. بهنجارسازی میتواند با روش چشمپوشی زمانی پویا صورت گیرد. این روش یک تابع بهینهی توسیع/ فشردهسازی زمانی را برای ایجاد صفبندی زمانی غیرخطی به کار میگیرد. شکل ۱ الگوها را پیش و پس از اعمال این روش نشان میدهد. به این نکته توجه شود که چگونه چشمپوشی الگوهای نمونهی آزمون میزان نزدیکی دو الگو را افزایش داده است:
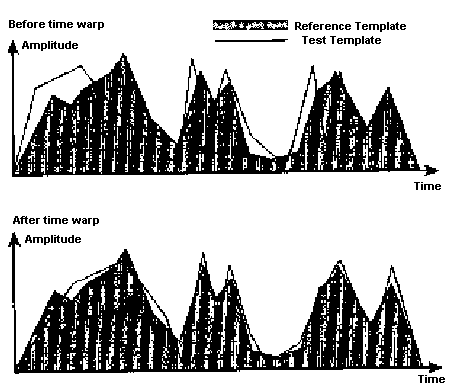
شکل شماره ۱ – نمونهی یک الگو پیش و پس از اعمال روش چشمپوشی زمانی پویا
در شکل شمارهی ۱ فریمهای صحبت که الگوهای آزمون و مرجع را به وجود میآورند به صورت مقادیر دامنهای اسکالر بر روی نموداری که محور افقی آن نشانگر زمان است نشان داده شدهاند. بنابراین یک تابع تصمیمگیری با جمعآوری اندازهگیریها بر حسب زمان میتواند محاسبه شود. در عمل الگوها بردارهای چند بعدی هستند و فاصله بین آنها به صورت فاصلهی اقلیدسی ((Euclidean distance)) مورد محاسبه قرار میگیرد. نوع دیگر فاصله که برای مقایسهی دو مجموعه از ضرایب پیشگویانهی خطی مورد استفاده قرار میگیرد فاصلهی ایتاکورا ((Itakura distance)) میباشد.
۳- روشهای مبتنی بر مدلهای نهان مارکف ((Hidden Markov Model [HMM]))
روشهای مبتنی برمدل نهان مارکف جایگزینهایی برای روش یکسانسازی الگوها که توسط روشهای چشمپوشی زمانی پویا ارائه شد میباشند که مدلهای احتمالی از سیگنال صحبت به وجود میآورند که ویژگیهای متغیر با زمان آن را توصیف میکند. یک مدل نهان مارکف یک فرایند اتفاقی دوگانه ((doubly stochastic process)) برای ایجاد یک دنباله از نشانههای مشاهده شده است. معنای دوگانه بودن این فرایند اتفاقی آن است که این فرایند دارای یک زیرفرایند اتفاقی دیگر است که قابل مشاهده نمیباشد (از اینجا مفهوم عبارت نهان مشخص میگردد) ولی میتواند توسط فرایند اتفاقی دیگری که یک دنباله از مشاهدات را ایجاد میکند مشاهده گردد. در سیستمهای نشخیص صحبت یا تشخیص گوینده دنبالهی موقتی طیف صوتی میتواند به صورت یک زنجیرهی مارکف ((Markov chain)) مدلسازی شود تا روشی را که یک صدا به صدای دیگری تبدیل میشود توصیف کند. این عمل سیستم را تا اندازهی یک مدل که قادر است فقط در یکی از یک تعداد متناهی از حالات متفاوت باشد (به عنوان نمونه یک ماشین حالت متناهی ((Finite State Machine [FSM])) کوچک میکند. روشهای مبتنی بر مدل نهان مارکف میتوانند هم در سیستمهای وابسته به متن و هم در سیستمهای مستقل از متن مورد استفاده قرار گیرند.
وقتی که بعد از یک انتقال حالت وارد یک حالت دیگر در ماشین حالت متناهی میشویم یک نشانه از مجموعه نشانههای آن حالت به عنوان خروجی برگزیده میشود. خروجی میتواند یک تعداد متناهی (روش مدل نهان مارکف گسسته) و یا یک مقدار پیوسته از خروجیها (روش توزیع پیوسته) باشد. هر دو مدل به صورت مؤثر اطلاعات موقتی را مدلسازی میکنند. سیستم در بازههای منظم زمانی تغییر حالت میدهد. حالتی که مدل در هر آغاز هر بازهی زمانی به آن میرود به احتمالات بستگی دارد.
تعدادی توپولوژی مدل که برای نمایش ماشین حالت متناهی استفاده میشوند وجود دارند. یک ساختار معمول ساختار چپ به راست است که به آن مدل بکیس ((Bakis model)) هم گفته میشود و مثال آن نمونهای است که در شکل ۲ نشان داده شده است. هر حالت یک انتقال توقف ((stay transition)) ، یک انتقال پیشرونده ((progressive transition)) و یک انتقال جهشی ((skip transition)) دارد. با وجود آن که دز شکل نشان داده نشده است احتمالهای مختلفی به انتقالهای حالت متناهی وابستهاند و همچنین خروجی هر حالت را کنترل میکنند. نوع دیگر توپولوژی مدل نهان مارکف که در اینجا نشان داده نشده ساختار ارگودیک ((ergodic)) میباشد که در آن همانند یک شبکهی کاملاُ متصل به هم هر حالت به همهی دیگر حالات دارای انتقال است.
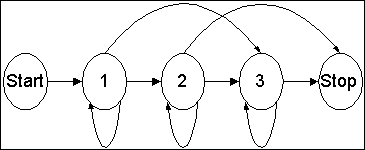
شکل شماره ۲ – مثالی از ساختار مدل نهان مارکف چپ به راست
۴- روشهای مبتنی بر مقدارگزینی برداری ((vector quantization [VQ]))
یک مجموعه از بردارهای خصیصهی بازهی کوتاه زمانی یک گوینده که برای آموزش سیستم به سیستم داده میشوند میتوانند مستقیماً برای نمایش ویژگیهای مهم عبارت ایراد شده توسط وی به کار گرفته شوند. در هر صورت نتیجهی کار آن است که نیازمندیهای حافظه برای ذخیرهی دادهها و پیچیدگی محاسباتی به سرعت با افزایش تعداد بردارهای آموزش دهندهی سیستم افزایش مییابد. بنابراین یک نمایش مستقیم عملی نخواهد بود.
مقدارگزینی برداری اساساً روشی برای فشردهسازی دادههای آموزش دهندهی سیستم تا اندازهای قابل مدیریت و کارا میباشد. با استفاده از یک دفتر کد ((codebook)) مقدارگزینی برداری که شامل تعداد کمی بردارهای خصیصه با نمایانگری بالاست میتوان دادههای اولیه را به مجموعهی کوچکی از نقاط نمایانگر کاهش داد. مقدارگزینی برداری هم در سیستمهای وابسته به متن و هم در سیستمهای مستقل از متن قابل استفاده است.
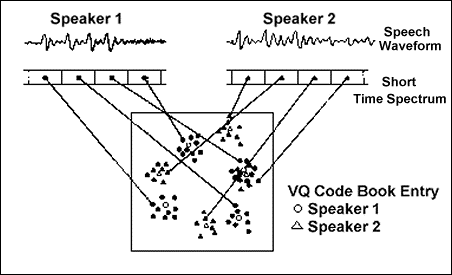
شکل شماره ۳ – نمودار مفهومی که شکلگیری یک دفتر کد مقدارگزینی برداری را به تصویر میکشد
شکل ۳ یک نمودار مفهومی را که مثالی از شکلگیری یک دفتر کد مقدارگزینی برداری را به تصویر میکشد نشان میدهد. یک گوینده میتواند بر اساس مکان مرکز ثقل بردارها از دیگری تشخیص داده شود. در شکل ۳ خصیصههای طیفی زمان کوتاه با یک فضای اقلیدسی دوبعدی نشان داده شدهاند. برای ایجاد یک مجموعه از نقاط گامهای زیر اجرا شدهاند:
– از دو گوینده خواسته شده تا چند دنباله عبارت برای آموزش سیستم بیان کنند.
– دنبالههای آموزش دهندهی سیستم تحلیل میشوند و برای آموزش دفتر کد مقدارگزینی برداری استفاده میگردند.
– سپس نقاط به بخشهای جداگانه افراز میگردند و دو دفتر کد تولید میگردد که هر کدام چهار عنصر دارند. عناصر دفتر کد مقدارگزینی برداری به صورت دایره و مثلث نمایش داده میشوند و مرکز ثقل بخشهای مرتبط با فضای خصیصهی هر گوینده را نشان می دهند.
همچنان که در شکل ۳ قابل مشاهده است با وجود کمی رویهمافتادگی دو دفتر کد هنوز کاملاُ مجزا هستند و بنابراین هر گوینده میتواند از دیگری تشخیص داده شود. هدف آموزش یک دفتر کد مقدارگزینی برداری یافتن افرازهای مناسب از یک فضای برداری به صورت تعدادی ناحیهی بدون رویهمافتادگی میباشد. هر افراز با یک بردار مرکز ثقل مرتبط نشان داده میشود. روشی معمول برای یافتن یک افرازبندی مناسب استفاده از یک رویهی بهینهسازی مانند الگوریتم تعمیمیافتهی لوید ((Loyd)) که آشفتگی متوسط در بین بردارهای آموزش سیستم و مرکز ثقلها را کمینه میکند میباشد. سایر روشها عبارتند از معیار کمترین بیشینه ((minimax criterion)) (کمینه کردن بیشترین آشفتگی) که الگوریتم پوشش ((covering algorithm)) نیز نامیده میشود و استفاده از قانون Kامین همسایهی نزدیک ((K-nearest neighbour)) به جای قانون نزدیکترین همسایه در محاسبهی آشفتگی.
۵- مقایسهی کارایی
آزمایشهای گوناگونی برای تعیین این که کدام روش برای تشخیص گوینده بهترین روش است صورت گرفته است و مهم است که به این نکته توجه شود که چگونه محققان مختلف در وضعیتهای گوناگون به نتایج متفاوتی دست پیدا نمودهاند. به عنوان نمونه اروین ((Irvine)) در نوشتار خود در ارتباط با آزمایشهایی که وی در زمینهی سیستمهای وابسته به متن برای مقایسهی سه روش برشمرده شده انجام داده است به این نتیجه رسیده است که روش مقدارگزینی برداری بهترین کارایی را ارائه میکند. حال آن که یو ((Yu)) ، میسن ((Mason)) و اگلبی ((Ogleby)) در مقالهی خود اشاره به اجرای آزمایشهایی مشابه نمودهاند که نتایج متفاوتی را احراز نمودهاند. نتیجهی تجربهی آنان که در بردارندهی آزمایشهایی برای سه روش توضیح داده شده برای سیستمهای وابسته به متن و دو روش متأخر برای سیستمهای مستقل از متن است نمودار شکل ۴ برای سیستمهای مستقل از متن و شکل ۵ برای سیستمهای مستقل از متن است. همچنان که در شکل ۴ مشاهده میشود بر اساس تجربیات این گروه روش چشمپوشی زمانی پویا دارای بهترین کارایی است و همچنین روشهای مدل نهان مارکف با چگالی پیوسته ((Continuous Density Hidden Markov Model [CDHMM])) و مقدارگزینی برداری هشتعنصری استفاده شده به ازای تعداد بردارهای آموزش سیستم متفاوت کاراییهای متفاوت دارند:
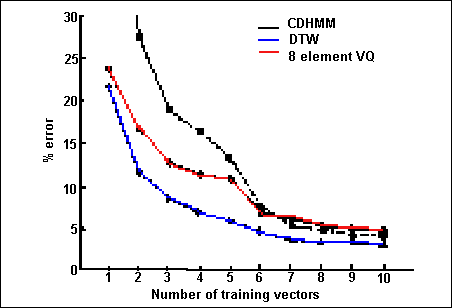
شکل شماره ۴ – درصد خطا بر اساس تعداد بردارهای آموزش سیستم برای روشهای وابسته به متن چشمپوشی زمانی پویا، مقدارگزینی برداری ۸عنصری و مدل نهان مارکف با چگالی پیوستهی ۸ حالتهی ۱ ترکیبه
همچنین از روی نمودار میتوان نتیجه گرفت که با وجود آن که برای تعداد بردارهای آموزش کم روش چشمپوشی زمانی پویا عملکرد بهتری دارد با افزایش تعداد بردارها این تفاوت عملکرد دیگر به صورت واضح مشاهده نمیشود.
شکل شمارهی ۵ نتیجهی تجربیات این گروه را برای سیستمهای مستقل از متن نشان میدهد:
از این شکل این گونه بر میآید که روش مدل نهان مارکف با چگالی پیوسته نیازمند تعداد بردارهای آموزش سیستم بیشتری میباشد.
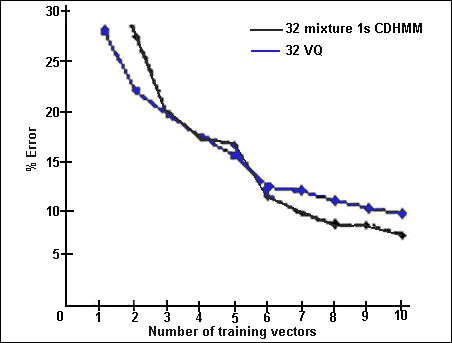
شکل شماره ۵ – درصد خطا بر اساس تعداد بردارهای آموزش سیستم برای روشهای مستقل از متن مقدارگزینی برداری ۳۲ عنصری و مدل نهان مارکف با چگالی پیوستهی تک حالتهی ۳۲ ترکیبه
ماتسوی ((Matsui)) و فروی ((Furui)) نیز سیستمهای مستقل از متن پیادهسازی شده با دو روش متأخر را مقایسه نمودند و اشاره نمودهاند که روش مدل نهان مارکف ارگودیک پیوسته در مقابل تغییرات عبارت پایداری همسانی با روش مقدارگزینی برداری دارد و عملکرد بسیار بهتری نسبت به روش مدل نهان مارکف ارگودیک گسسته دارد. آنها همچنین به نتیجهای مشابه با گروه قبلی دست یافتهاند و آن این است که سیستمهای مبتنی بر روش مقدارگزینی برداری برای مقادیر کم داده پایدارتر از سیستمهای مبتنی بر روش مدل نهان مارکف پیوسته میباشند. شکل ۶ نتیجهی تجربیات آنان را به تصویر میکشد:
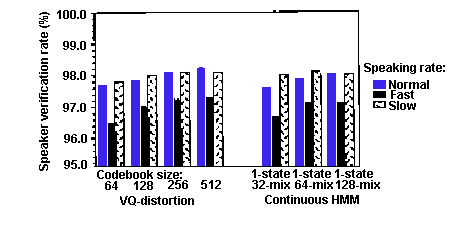
شکل شماره ۶ – مقایسهی سیستمهای مستقل از متن (ماتسوی و فوروی ۱۹۹۲)
۶- منابع فصل
1) Woon Wei Kian and Yap Wei Wum, Approaches to Speaker Verification Methods (Part of an article titled as Surprise 98 … reporting on Speaker Verification), from http://www.iis.ee.ic.ac.uk/~frank/surp98/report/wwy2/approaches.htm