۱- دستگاه شنوایی انسان
پردازش صوت محدودههای گوناگونی را در بر میگیرد که همه به منظور ارائهی صدا به شنوندگان انسانی ابداع شدهاند. سه محدودهی تکثیر موسیقی با کیفیتی به خوبی اصل همانند آنچه در سیدیهای صوتی وجود دارد ،ارتباط صوتی از راه دور که نام دیگر شبکهی تلفنی است و ،ترکیب صحبت که در آن کامپیوترها الگوهای صوتی انسان را تولید کرده یا تشخیص میدهند از دیگر قلمروهای دانش پردازش صوت مهمترند. با وجود این که اهداف و مسائل این کاربردها متفاوتند همگی در یک نقطهی مشترک به هم میرسند و آن گوش انسان است.
گوش انسان یک عضو به گونهای فزاینده پیچیده است. قضیه وقتی پیچیدهتر میشود که اطلاعات ارسالی از دو گوش در یک شبکهی پیچیدهی گیج کننده که همانا مغز انسان باشد با هم ترکیب میشوند. به یاد داشته باشیم که بیان فوق یک گذر کلی بر قضیه است و تعداد زیادی از پدیدهها و آثار دقیق مرتبط با گوش انسان هنوز به درستی درک نشدهاند.
شکل ۱ قسمت اعظم ساختارها و پردازشهایی را که گوش انسان را در بر دارند به تصویر میکشد. گوش خارجی از دو بخش تشکیل شده است: نرمی پوست قابل مشاهده و غضروف متصل به کنار سر و کانال گوش که لولهایست به قطر تقریبی ۰.۵ سانتیمتر و تا حدود ۳ سانتیمتر در داخل سر فرو میرود. این ساختارها صداهای محیط را به بخشهای حساس گوش میانی و گوش داخلی که در درون استخوانهای جمجمه محافظت میشود راهبری میکنند. در انتهای کانال گوش یک ورقهی نازک از نسوج که پردهی صماخ ((tympanic membrane)) یا طبل گوش نامیده میشود کشیده شده است. امواج صدا با برخورد به پردهی صماخ باعث لرزش آن میشوند. گوش میانی مجموعهای از استخوانهای کوچک است که لرزش مزبور را به حلزون گوش ((cochlea)) (گوش داخلی) انتقال میدهند و در آنجا این لرزشها تبدیل به ضربههای عصبی میگردند. حلزون گوش یک لولهی پر از مایع است که به زحمت قطر آن به ۲ میلیمتر و طول آن به ۳ سانتیمتر میرسد. اگر چه حلزون گوش در شکل شماره ۱ به صورت یک لولهی مستقیم نشان داده شده اما در واقع به دور خودش همانند صدف حلزون پیچ خورده است و وجه تسمیهی آن که ریشه در کلمهای یونانی به معنای حلزون دارد نیز این واقعیت است.
وقتی یک موج صوتی سعی دارد از هوا وارد مایع شود تنها کسر کوچکی از آن از بین دو محیط عبور میکند و باقیماندهی انرژی آن بازتابیده میشود. دلیل این امر مقاومت مکانیکی پایین هوا (ناشی از پایین بودن میزان فشار صوتی و سرعت بالای ذرات هوا که به نوبهی خود از چگالی پایین و تراکمپذیری بالای آنها نشأت میگیرد) در برابر مقاومت مکانیکی بالای مایع است. به عبارت سادهتر دلیل این امر مشابه دلیل این موضوع است که برای ایجاد موج با دست در درون آب به تلاش بیشتری به نسبت انجام این کار در هوا نیازمندیم. تفاوت موجود باعث بازتابش قسمت اعظم صوت در مرز هوا/مایع میگردد.
گوش میانی یک شبکهی تطبیق مقاومت ((impedance matching)) است که کسر انرژی صوتی وارد شده به مایع گوش داخلی را زیاد میکند. برای نمونه ماهی پردهی صماخ یا گوش میانی ندارد چرا که نیازی به شنیدن در هوا ندارد. تغییر شدت، بیشتر ناشی از تفاوت مساحت پردهی صماخ (که صدا را از هوا دریافت میکند) و دریچه بیضوی ((oval windows)) (که مطابق شکل ۱صدا را به داخل مایع انتقال میدهد) میباشد. مساحت پردهی صماخ حدوداً ۶۰ میلیمتر مربع است حال آن که دریچهی بیضوی حدوداً ۴ میلیمتر مربع مساحت دارد. از آنجا که فشار برابر است با نسبت نیرو به مساحت، این تفاوت مساحت فشار موج صدا را حدوداً ۱۵ برابر افزایش میدهد.
در داخل حلزون گوش پردهی اصلی ((basilar membrane)) قرار دارد که ساختاری را برای ۱۲۰۰۰ سلول حسی که شکلدهندهی عصب حلزونی است ایجاد میکند. پردهی اصلی در نزدیکی دریچهی بیضوی بسیار سفت است و در انتهای دیگر انعطافپذیرتر است که این امر به این عضو کمک میکند تا به عنوان تحلیلگر طیف فرکانسی عمل کند. وقتی پردهی اصلی در معرض یک سیگنال با فرکانس بالا قرار میگیرد در قسمت سفتتر طنین میاندازد که سبب تحریک سلولهای عصبی نزدیک به دریچهی بیضوی میگردد. به همین ترتیب فرکانسهای پایین موجب تحریک انتهای دورتر پردهی اصلی میشوند. این امر موجب پاسخگویی رشتههای خاص عصب حلزونی در برابر فرکانسهای خاص میگردد. این سازوکار اصل مکان ((place principle)) نامیده میشود و در سراسر مسیر به سمت مغز حفظ میشود.
طرح کدگذاری اطلاعات دیگری نیز در شنوایی انسان به کار میرود که اصل رگبار ((volley principle)) نامیده میشود. سلولهای عصبی اطلاعات را با تولید پالسهای الکتریکی کوچکی که پتانسیل کنش ((action potential)) نامیده میشوند انتقال میدهد. یک سلول عصبی واقع بر پردهی پایینی میتواند اطلاعات صوتی را با تولید یک پتانسیل کنش در پاسخ هر سیکل لرزش کدگذاری کند. برای نمونه یک موج صدای ۲۰۰ هرتزی میتواند توسط یک نورون ایجاد کنندهی ۲۰۰ پتانسیل کنش در ثانیه نشان داده شود. در هر صورت این روش تنها در فرکانسهای زیر حدوداً ۵۰۰ هرتز – بالاترین سرعت ممکن تولید پتانسیل کنش در نورونها – به کار میآید. گوش انسان برای غلبه بر این مشکل به نورونها اجازه میدهد که برای انجام این کار دستهجمعی عمل کنند. برای نمونه یک صدای ۳۰۰۰ هرتزی میتواند توسط ده سلول عصبی که هر کدام ۳۰۰ ضربه در ثانیه علامت میدهند نشان داده شود. این پدیده بازهی کارایی اصل رگبار را تا ۴ کیلوهرتز گسترش میدهد که بالاتر از بازهی عملیاتی اصل مکان میباشد.
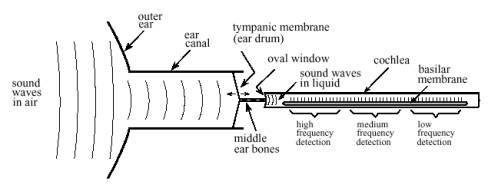
شکل شماره ۱- توضیحات مربوط به شکل: نمودار کارکردی گوش انسان. گوش خارجی امواج صوتی را از محیط میگیرد و آنها را به سوی پردهی صماخ (طبل گوش) که ورقهی نازکی از بافت است و هماهنگ با شکل موج هوا میلرزد راهبری میکند. استخوانهای گوش میانی (استخوانهای چکشی، سندانی و رکابی) این لرزشها را به دریچهی بیضوی که پردهای منعطف واقع در حلزون گوش پر از مایع است انتقال میدهند. در داخل حلزون گوش پردهی اصلی قرار دارد که ایجاد کنندهی ساختاری برای ۱۲۰۰۰ سلول عصبی شکلدهندهی عصب حلزون گوش است. بسته به سفتی متغیر پردهی پایینی، هر سلول فقط به بازهی کوچکی از فرکانسهای صدا پاسخ میدهد که این پدیده گوش را تبدیل به یک تحلیلگر طیف فرکانسی مینماید.
شکل شماره ۲ رابطهی بین شدت صدا و بلندی مشاهده شده را نشان میدهد. غالباً شدت صدا را با یک اندازهی لگاریتمی که دسیبل اس.پی.ال. ((decibel SPL)) (سطح توان صدا) نامیده میشود نشان میدهند. در این معیار ۰ دسیبل اس.پی.ال موج صدایی با قدرت ده به توان منفی شانزده وات بر سانتیمتر مربع است که حدوداً ضعیفترین صدای قابل تشخیص توسط گوش انسان است. صحبت معمولی حدوداً ۶۰ دسیبل اس.پی.ال است و صدایی با شدت ۱۴۰ دسیبل اس.پی.ای برای گوش دردناک و زیانآور است.
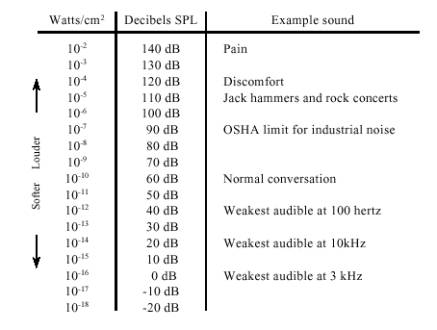
شکل شماره ۲ – واحدهای شدت صدا. شدت صدا به صورت توان بر واحد مساحت تعریف میشود (مثلاُ وات بر سانتیمتر مربع) یا به صورت معمولتر با استفاده از یک اندازهی لگاریتمی که دسیبل اس.پی.ال خوانده میشود. همچنان که این جدول نشان میدهد قوهی شنوایی انسان بیشتر به صداهای بین ۱کیلوهرتز تا ۴ کیلوهرتز حساس است.
اختلاف بلندترین و ضعیفترین صداهایی که انسان میتواند بشنود ۱۲۰ دسیبل است که از لحاظ دامنه معادل بازهای حدود یک میلیون است. شنونده تغییر بلندی صدا را وقتی صدا حدود ۱ دسیبل (۱۲% در دامنه) تغییر کند تشخیص میدهد به عبارت دیگر تنها ۱۲۰ سطح بلندی صدا از ملایمترین نجوا تا بلندترین تندر قابل تشخیص است. حساسیت گوش آنقدر جالب توجه است که هنگام شنیدن به ضعیفترین صداها پردهی صماخ به اندازهای کمتر از قطر یک ملکول به لرزش درمیآید!
احساس بلندی صدا با توان صدا رابطهی توانی با نمای ۱/۳ دارد. به عنوان نمونه اگر شما توان صدا را ده برابر کنید شنوندگان آن صدا دو برابر شدن بلندی صدا را احساس و گزارش میکنند.
این مسأله یک مشکل بزرگ برای حذف صداهای محیطی ناخواسته به وجود میآورد. برای نمونه فرض کنید که شما ۹۹% دیوار را با عایق صوتی پوشاندهاید و تنها ۱% که مربوط به درها، گوشهها، منافذ و… هستند باقی ماندهاند. با وجود آن که توان صدا تا اندازهی ۱% مقدار اولیهی آن کاسته شده بلندی صدا تنها به اندازهی ۲۰% کاهش پیدا کردهاست.
بازهی شنیداری انسان بین ۲۰ هرتز تا ۲۰ کیلوهرتز در نظر گرفته میشود، حال آن که بیشتر صداهای قابل حس در بازهی ۱ کیلوهرتز تا ۴ کیلوهرتز قرار دارند. برای نمونه شنوندگان میتوانند صدایی به میزان صفر دسیبل را در فرکانس ۳ کیلوهرتز بشنوند حال آن که برای شنیدن یک صدای ۱۰۰ هرتزی حداقل مقدار آن باید ۴۰ دسیبل باشد. شنوندگان میتوانند بگویند که دو صدا متفاوتند اگر فرکانس آنها بیش از حدود ۰.۳% در ۳ کیلوهرتز متفاوت باشد. به عنوان نمونه کلیدهای کنار هم در پیانو به اندازهی حدود ۶% تفاوت فرکانس دارند.
مهمترین مزیت داشتن دو گوش تشخیص جهت صداست. شنوندگان انسانی میتوانند تفاوت بین دو منبع صدا را که فاصلهای به کمی ۳ درجه دارند (حدوداً برابر با عرض یک انسان در فاصلهی ده متری) تشخیص دهند. این اطلاعات جهتی به دو روش جداگانه به دست میآیند. اولاً فرکانسهای حدوداً بالای ۱ کیلوهرتز به شدت زیر سایهی سر قرار میگیرند. به بیان دیگر گوشی که به منبع نزدیکتر است سیگنال قوی تری را به نسبت گوشی که در جهت مخالف دارد دریافت میکند. روش دیگر تشخیص جهت آن است که گوش دورتر به خاطر فاصلهی بیشترش از منبع صدا را کمی دیرتر از گوش نزدیکتر دریافت میکند. به واسطهی اندازهی معمول سر (حدوداً ۲۲ سانتیمتر) و سرعت صوت (حدود ۳۴۰ متر در ثانیه) تفاوتگذاری زاویهای سه درجه دقت زمانی حدود ۳۰ میکروثانیه نیاز دارد. چون این فاصلهی زمانی نیازمند اصل رگبار است این روش جهتیابی برای صداهای دارای فرکانس کمتر از حدود ۱ کیلوهرتز به کار میرود.
در حالی که قوهی شنوایی انسان میتواند جهت صدا را تشخیص دهد در نشخیص فاصلهی منبع صدا مشکل دارد. این امر بدان علت است که چیزهای کمی در موج صدا وجود دارد که اطلاعات این گونه را در اختیار بگذارد. شنوایی انسان به صورت ضعیفی در مییابد که منابع صداهای با فرکانس بالا نزدیکند و صداهای با فرکانس پایین از فاصلهی دورتری پخش میشوند. این به آن دلیل است که صداها در فاصلههای دور از میزان فرکانسشان کاسته میشود. پژواک روش ضعیف دیگری برای تشخیص فاصله است و با استفاده از آن مثلاً میتوان ابعاد یک اتاق را حدس زد. برای نمونه صداهای موجود در یک تالار بزرگ پژواکهایی با وقفهی ۱۰۰ میلی ثانیه دارند، حال آن که برای یک دفتر کار کوچک این مقدار ۱۰ میلی ثانیه است. بعضی از موجودات با استفاده از دستگاه طبیعی تشخیص فاصلهی صوتی ((sonar)) مسألهی فاصلهیابی را حل کردهاند. مثلاً خفاشها و دلفینها صداهایی مثل تیک و جیغ تولید میکنند که از سوی اشیاء نزدیک بازتابیده میشوند. با اندازهگیری میزان وقفهی بازتاب این صداها این جانوران میتوانند با دقت ۱سانتیمتر اشیاء را مکانیابی کنند. تجربیات نشان دادهاند که بعضی انسانها به خصوص نابینایان تا حد کمی از روش مکانیابی با استفاده از پژواک استفاده میکنند.
۲- ویژگیهای امواج صوتی
غالباً برای درک یک صوت پیوسته مثل نت یک ابزار موسیقیایی سه بخش مجزا را باید تشخیص داد: بلندی صدا، زیری یا بمی صدا (پیچ ((pitch))) و طنین صدا ((timbre)). بلندی همانگونه که قبلاً توضیح داده شد معیاری برای شدت موج صوتی است. پیچ، فرکانس جزء اصلی صدا – فرکانسی تکرار موج صوتی توسط خودش – میباشد.
طنین صدا از دو جزء قبلی پیچیدهتر است و با تعیین محتوای همساز ((harmonic content)) صدا تعیین میگردد. شکل شماره ۳ دو موج را که هر دو از جمع یک موج سینوسی یک کیلوهرتزی با دامنهی یک و یک موج سینوسی سه کیلوهرتزی با دامنهی یک دوم به وجود آمدهاند نشان میدهد. تفاوت آنها در آن است که در شکل b جزء با فرکانس بالاتر ابتدا معکوس شده و سپس با موج دوم جمع شده است. علیرغم موجهای در دامنهی زمان بسیار متفاوت این دو صوت یکسان به نظر میرسند. این به خاطر آن است که شنوایی انسان بر اساس دامنهی فرکانسهاست و نسبت به فاز آنها بسیار غیر حساس است. شکل موج صوتی در دامنهی زمان فقط به صورت غیر مستقیم با شنوایی رابطه دارد و معمولاُ در سیستمهای صوتی در نظر گرفته نمیشود.
عدم حساسیت گوش به فاز صدا با توجه به روش پخش شدن آن در محیط قابل درک است. فرض کنید که شما در یک اتاق به صحبتهای فردی گوش میدهید. بیشتر صداهایی که گوش شما دریافت میکند حاصل بازتاب صدای اصلی از دیوارها، سقف و کف اتاق است. از آنجا که انتشار صدا بستگی به فرکانس آن دارد و میرایی ،بازتاب و مقاومت در برابر صدا بر روی آن تأثیرگذار است فرکانسهای متفاوتی از مسیرهای متفاوت به گوش میرسد. این به این معنی است که وقتی شما جای خود را در اتاق عوض میکنید فاز هر یک از فرکانسها تغییر میکند. چون گوش این تغییر فازها را نادیده میانگارد با وجود تغییر مکان شما تغییری در صدای شخص صحبت کننده احساس نمیکنید. از دیدگاه فیزیکی فاز یک سیگنال صدا در هنگام پخش در یک محیط پیچیده به صورت تصادفی تغییر میکند. از طرف دیگر گوش به فاز صدا غیر حساس است زیرا این جزء دارای اطلاعات قابل استفادهی بسیار کمی میباشد.
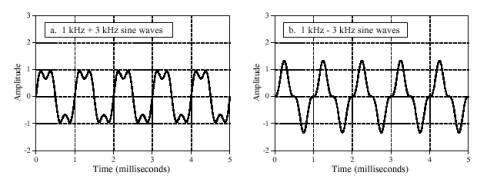
شکل شماره ۳ – تشخیص فاز توسط گوش انسان. گوش انسان نسبت به فاز نسبی سینوسیهای مرکب بسیار غیر حساس است. برای نمونه این دو موج یکسان به نظر خواهند رسید، زیر دامنهی اجزاء آنها یکسان است اگر چه فاز نسبی آنها متفاوت است.
در حالت کلی نمیتوان گفت که گوش نسبت به فاز کاملاً ناشنواست. چرا که تغییر فاز میتواند باعث تغییر آرایش زمانی یک سیگنال صوتی شود. اما چنین امری یک پدیدهی نادر است که در محیطهای شنیداری طبیعی اتفاق نمیافتد.
فرض کنید از یک نوازندهی ویولون خواستهایم نتی را بنوازد. وقتی که موج صوتی ایجاد شده بر روی اسیلوسکوپ نشان داده شود یک موج دندانهارهای مانند شکل شماره ۴ (a) مشاهده میشود. شکل شماره ۴ (b) نشان میدهد که این صوت چگونه توسط گوش دریافت میشود. گوش یک فرکانس اساسی (در مثال شکل ۲۲۰ هرتز) را و همسازهایی را در ۴۴۰، ۶۶۰، ۸۸۰ و… هرتز دریافت میکند. اگر این نت بر روی ابزار دیگری نواخته شود گوش هنوز هم همان ۲۲۰ هرتز (همان فرکانس اساسی) را دریافت میکند. و از این لحاظ دو صوت مشابهند که گفته میشود این دو صوت پیچ یکسانی دارند ولی چون دامنهی همسازها متفاوت است دو صوت یکسان نیستند و گفته میشود که طنین دو صوت متفاوت است.
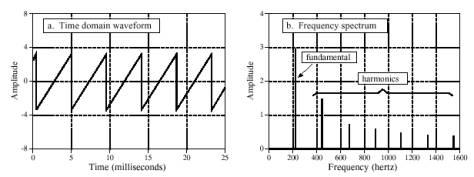
شکل شماره ۴ – موج صوتی ویولن. ویولن موج دندانهارهای ایجاد میکند (شکل a)، صدای دریافت شده شامل فرکانس اساسی و همسازهای آن است (شکل b)
اغلب گفته میشود که طنین صدا از روی شکل موج صوتی تعیین میگردد. این مسأله درست است ولی کمی گمراه کننده است. احساس طنین صدا از روی میزان هارمونیکهای تشخیص داده شده توسط گوش تعیین میگردد. در حالی که هارمونیکها از روی شکل موج صوتی تعیین میگردد عدم حساسیت گوش به فاز رابطه را بسیار یک طرفه میکند. به همین دلیل هر موج صوتی فقط یک طنین دارد حال آن که یک زنگ خاص متعلق به تعداد بینهایتی از موجهای صوتی است.
گوش بیشتر برای شنیدن هارمونیکهای اساسی تنظیم شده است. اگر یک شنونده به صدایی که حاصل ترکیب دو موج صوتی سینوسی ۱ کیلوهرتز و ۳ کیلوهرتز است گوش دهد آن را مطلوب و طبیعی توصیف خواهد کرد حال آن که اگر از موجهای ۱ کیلوهرتزی و ۳.۱ کیلوهرتزی استفاده شود برای شنونده شکایت برانگیز خواهد بود. این مسأله اساسی برای اندازهها و اختلافهای استاندارد ابزارهای موسیقیایی فراهم میآورد.
۳- روشهای دیجیتالی ذخیرهی صدا
در طراحی یک سیستم صوتی دیجیتال دو پرسش وجود دارند که باید پاسخ داده شوند: ۱- چقدر لازم است صوت خوب به نظر برسد؟ ۲- چه نرخ دادهای قابل تحمل است؟ جواب به این پرسشها غالباً به یکی از این سه انتخاب منجر میشود: اول موسیقی با وفاداری بالا ((high fidelity music)) که در آن کیفیت صدا مهمترین چیز است و تقریباً هر نرخ دادهای قابل قبول است. دوم ارتباط تلفنی ((telephone communication)) که نیازمند طبیعی به نظر رسیدن صحبت و یک نرخ دادهی پایین برای کاهش هزینهی سیستم است. سوم صحبت فشرده شده ((compressed speech)) که در آن کاهش نرخ داده بسیار مهم است و مقداری غیر طبیعی به نظر رسیدن کیفیت صدا قابل تحمل است. این مورد در بر دارندهی ارتباطات نظامی، تلفنهای سلولی و صحبت ذخیره شده به صورت دیجیتال برای پست الکترونیکی صوتی یا کاربردهای چند رسانهای است.
شکل شماره ۵ بده بستانهای موجود در انتخاب هر یک از این سه روش را نشان میدهد.
در حالی که موسیقی نیازمند پهنای باند ۲۰ کیلوهرتز است صحبتی که طبیعی به نظر برسد فقط به پهنای باندی در حدود ۳.۲ کیلوهرتز نیازمند است. در این حال هر چند پهنای باند به اندازهی ۱۶% مقدار اولیه محدود میشود ولی فقط ۲۰% اطلاعات اولیه از دست میرود.
سیستمهای ارتباط راهدور اغلب از نرخ نمونهبرداری در حدود ۸ کیلوهرتز استفاده میکنند که اجازهی انتقال صحبت را با کیفیتی در حد طبیعی میدهد ولی اگر از آن برای انتقال موسیقی استفاده شود تا میزان بالایی از کیفیت آن از دست میرود. شما احتمالاً با تفاوت این دو میزان آشنایی دارید: ایستگاههای رادیویی اف.ام با پهنای باندی در حدود ۲۰ کیلوهرتز اقدام به پخش میکنند حال آن که ایستگاههای ای.ام محدود به ۳.۲ کیلوهرتز هستند. صحبت و صداهای معمول روی ایستگاههای نوع دوم طبیعی به نظر میرسد حال آن که موسیقی این گونه نیست.
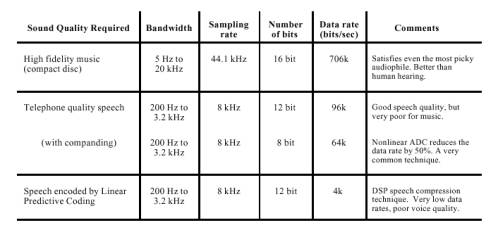
شکل شماره ۵ – نرخ دادهی صوتی در برابر کیفیت صدا. کیفیت صدای یک سیگنال صوتی دیجیتال به نرخ دادهی آن که برابر با حاصلضرب نرخ نمونهبرداری آن در تعداد بیتهای آن در هر نمونه بستگی دارد که به سه بخش تقسیم میشود: موسیقی باوفاداری بالا (۷۰۶کیلوبیت بر ثانیه)، صحبت با کیفیت تلفن (۶۴کیلوبیت بر ثانیه) وصحبت فشرده شده (۴ کیلوبیت بر ثانیه)
سیستمهایی که فقط با صدا (و نه موسیقی) سر و کار دارند میتوانند مقدار دقت را از ۱۶ بیت به ۱۲ بیت بدون از دست رفتن دقتی قابل توجه کاهش دهند. این میزان میتواند با انتخاب اندازهی نامتساوی برای گام مقدارگزینی ((quantization step)) میتواند به ۸ بیت در هر نمونه نیز کاهش یابد. یک نرخ نمونهبرداری ۸ کیلوهرتز با دقت ای.دی.سی ۸ بیت در هر نمونه به نرخ دادهی ۶۴کیلوبیت بر ثانیه میانجامد. این یک حد نهایی برای طبیعی به نظر رسیدن صحبت است. دقت کنید که صحبت نیازمند نرخ دادهای معادل ۱۰% نرخ دادهی موسیقی با وفاداری بالاست.
نرخ دادهی ۶۴ کیلو بیت بر ثانیه نمایانگر کاربرد نهایی نظریهی نمونهبرداری و مقدارگزینی برای سیگنالهای صوتی است. روشهای کاهش نرخ داده به اندازهای بیشتر از این مبتنی بر فشردهسازی جریان داده با حذف تکرارهای ذاتی سیگنال صحبت است. یکی از کاراترین روشهای موجود ال.پی.سی ((LPC [Linear Predictive Coding])) است که انواع و زیرگروههای متعدد دارد. بر اساس کیفیت سیگنال صحبت مورد نیاز این روش میتواند نرخ داده را تا اندازهای بین ۲ تا ۶ کیلو بیت بر ثانیه کاهش دهد.
۴- منابع فصل
1) Steven W. Smith,The Scientist and Engineer’s Guide to Digital Signal Processing, Chapter 22: Audio Processing, from www.dspguide.com
یک دیدگاه برای “پردازش صوت : پیشزمینههای تئوری”
دیدگاهها بسته شدهاند.