۱- ترکیب و تشخیص صحبت
کاربردهای نیازمند پردازش صحبت اغلب در دو دستهی ترکیب صحبت ((speech sysnthesis)) و تشخیص صحبت ((speech recognition)) مورد بررسی قرار میگیرند.
ترکیب صحبت عبارت است از فنآوری تولید مصنوعی صحبت به وسیلهی ماشین و به طور عمده از پروندههای متنی به عنوان ورودی آن استفاده میگردد. در اینجا باید به یک نکتهی مهم اشاره شود که بسیاری از تولیدات تجاری که صدای شبیه به صحبت انسان ایجاد میکنند در واقع ترکیب صحبت انجام نمیدهند بلکه تنها یک تکهی ضبط شده به صورت دیجیتال از صدای انسان را پخش میکنند. این روش کیفیت صدای بالایی ایجاد میکند اما به واژهها و عبارات از پیش ضبط شده محدود است. از کاربردهای عمدهی ترکیب صحبت میتوان به ایجاد ابزارهایی برای افراد دارای ناتوانی بینایی برای مطلع شدن از آنچه بر روی صفحهی کامپیوتر میگذرد اشاره کرد.
تشخیص صحبت عبارت است از تشخیص کامپیوتری صحبت تولید شده توسط انسان و تبدیل آن به یک سری فرامین یا پروندههای متنی. کاربردهای عمدهی موجود برای این گونه سیستمها دربرگیرندهی بازهی گستردهای از سیستمها وکاربردها از سیستمهای دیکتهی کامپیوتری که در سیستمهای آموزشی و همچنین سیستمهای پردازش واژه کاربرد دارد گرفته تا سیستمهای کنترل کامپیوترها به وسیلهی صحبت و به طور خاص سیستمهای فراهم آورندهی امکان کنترل کامپیوترها برای افراد ناتوان از لحاظ بینایی یا حرکتی میباشد.
کاربرد مورد نظر ما یعنی تشخیص گوینده از لحاظ نحوهی پیادهسازی و استفاده تناسب فراوانی با خانوادهی دوم یعنی تشخیص کامپیوتری صحبت دارد، ولی از لحاظ اهداف و کاربردها میتواند در خانوادهای جداگانه از کاربردهای نیازمند پردازش صحبت قرار گیرد.
ترکیب و تشخیص کامپیوتری صحبت مسائل دشواری هستند. روشهای مختلفی مورد آزمایش قرار گرفتهاند که موفقیت کمی داشتهاند. این زمینه از زمینههای فعال در تحقیقات پردازش سیگنال دیجیتال (دی.اس.پی) بوده و بدون شک سالها این گونه خواهد ماند. در حال حاضر از ابزارهای برنامهنویسی جاافتاده در زمینههای برشمرده شده میتوان به ای.پی.آی صحبت شرکت مایکروسافت ((Microsoft SAPI)) اشاره نمود که دارای تواناییهای عمدهای در زمینههای تشخیص و ترکیب صحبت است و توانایی آن تا حدی گسترده است که در محصول بزرگ و توانمند MS Office XP از آن استفادهی عملی شده است. ابزار عمدهی دیگر تولید شرکت آی.بی.ام است و ViaVoice نام دارد که به لحاظ پشتیبانی آن برای سیستمعاملهای متعدد و زبانهای گوناگون از اهمیت و کاربرد خاصی برخوردار است.
۲- مدلی برای توصیف روش تولید صحبت
تقریباً تمام تکنیکهای ترکیب و تشخیص صحبت بر اساس مدل تولید صحبت انسان که در شکل شماره ۳ نشان داده شده است ایجاد شدهاند. بیشتر صداهای مربوط به صحبت انسان به دو دستهی صدادار ((voiced)) و سایشی ((fricative)) تقسیم میشوند. اصوات صدادار وقتی که هوا از ریهها و از مسیر تارهای صوتی به بیرون دهان یا بینی رانده میشوند ایجاد میگردند. تارهای صوتی دو رشتهی آویخته از بافت هستند که در مسیر جریان هوا کشیده شدهاند. در پاسخ به کشش ماهیچهای متفاوت تارهای صوتی با فرکانسی بین ۵۰ تا ۱۰۰۰هرتز ارتعاش میکنند که باعث انتقال حرکتهای متناوب هوا به نای میشود. در شکل شماره ۳ اصوات صدادار با یک مولد پالس ترِین ((pulse train generator)) با پارامتر قابل تنظیم پیچ (فرکانس پایهی موج صوتی) نشان داده شده است.
در مقایسه، اصوات سایشی به صورت نویز تصادفی و نه حاصل از ارتعاش تارهای صوتی به وجود میآیند. این حادثه زمانی رخ میدهد که تقریباً جریان هوا به وسیلهی زبان و لبها یا دندانها حبس میشود که این امر باعث ایجاد اغتشاش هوا در نزدیکی محل فشردگی میگردد
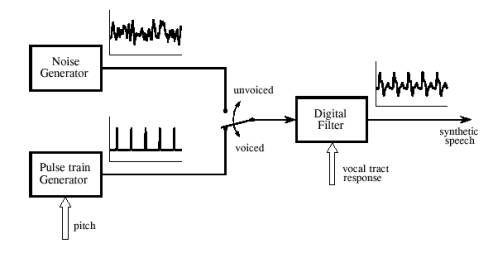
شکل شماره ۳ – مدل صحبت انسان. در یک تکه زمان کوتاه، حدود ۲ تا ۴۰ میلیثانیه صحبت میتواند با استفاده از سه پارامتر مدلسازی شود: ۱- انتخاب یک آشفتگی متناوب یا نویزوار. ۲- پیچ آشفتگی متناوب ۳- ضرایب یک فیلتر خطی بازگشتی که پاسخ اثر صوتی را تقلید میکند.
اصوات سایشی زبان انگلیسی عبارتند از s، f، sh، z، v و th. در مدل شکل شماره ۳ اصوات سایشی با استفاده از یک مولد نویز نشان داده شدهاند.
هر دو نوع این اصوات، توسط چالههای صوتی که از زبان، لبها، دهان، گلو و گذرگاههای بینی تشکیل شدهاند دچار تغییر میشوند. چون انتشار صدا در این ساختارها یک فرایند خطی است میتواند با استفاده از یک فیلتر خطی با یک پاسخ ضربهی مناسب نمایش داده شود. در بیشتر موارد از یک فیلتر بازگشتی که ضرایب بازگشتی آن ویژگیهای فیلتر را مشخص میکند استفاده میشود. به خاطر این که چالههای صوتی ابعادی به اندازهی چند سانتیمتر دارند پاسخ فرکانسی یک دنباله از تشدیدها با اندازههای کیلوهرتزی است. در اصطلاح پردازش صوت این قلههای تشدید فرکانسهای فرمانت ((formant frequencies)) خوانده میشوند. با تغییر جایگاه نسبی زبان و لبها فرکانسهای فرمانت هم از لحاظ دامنه و هم از لحاظ فرکانس ممکن است تغییر کنند.
شکل شماره ۴ یک روش معمول برای نمایش سیگنالهای صحبت را نشان میدهد که طیفنگاره ((specrogram)) یا اثر صوت ((voice print)) خوانده میشود. سیگنال صوتی به تکههای کوچک به اندازهی ۲ تا ۴۰ میلیثانیه تقسیم میشوند و از الگوریتم اف.اف.تی برای یافتن طیف فرکانسی هر تکه استفاده میشود. این طیفها در کنار هم قرار داده شده تبدیل به یک تصوبر سیاه و سفید ((grayscale)) میشود (دامنههای پایین روشن و دامنههای بالا تیره میشوند). این کار یک روش گرافیکی برای مشاهدهی این که چگونه محتویات فرکانسی صحبت با زمان تغییر میکند به وجود میآورد. اندازهی هر تکه بر اساس اعمال یک بدهبستان بین دقت فرکانسی (که با تکههای بزرگتر بهتر میشود) و دقت زمانی (که با تکههای کوچکتر بهتر میشود) انتخاب میگردد.
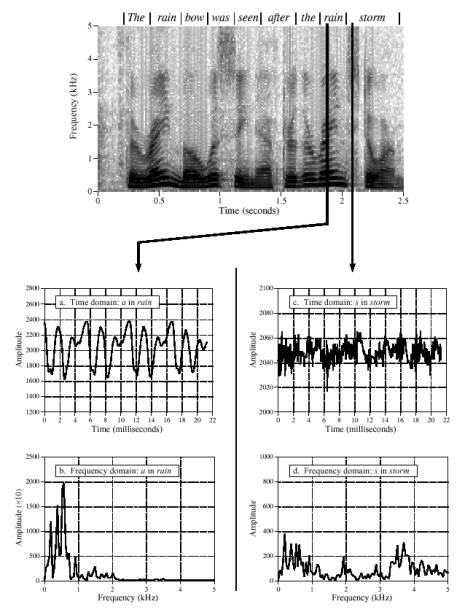
شکل شماره ۴- طیف صوت. شکلهای a و b ویژگیهای عمومی اصوات صدادار و شکلهای c و d ویژگیهای عمومی اصوات سایشی را نمایش میدهند.
همچنانکه در شکل ۴ دیده میشود اصوات صدا دار مثل a در rain دارای موج صوتی متناوبی مانند آنچه در شکل a نشان داده شده و طیف فرکانسی آنها که عبارت است از یک دنباله از همسازهای با اندازهی منظم مانند شکل b میباشد در مقابل، اصوات سایشی مانند s در storm دارای یک سیگنال نویزی در دامنهی زمان مانند شکل c و یک طیف نویزی مانند شکل d هستند.این طیفها همچنین شکل فرکانسهای فرمانت برای هر دو نوع صوت نشان میدهند. همچنین به این نکته توجه کنید که نمایش زمان-فرکانس کلمهی rain در هر دو باری که ادا شده شبیه به هم است.
در یک دورهی کوتاه برای نمونه ۲۵ میلیثانیه یک سیگنال صحبت میتواند با مشخص کردن سه پارامتر تقریب زده شود:
۱) انتخاب یک اغتشاش متناوب یا نویزوار
۲)فرکانس موج متناوب (اگر مورد استفاده قرار گرفته باشد)
۳)ضرایب فیلتر دیجیتالی که برای تقلید پاسخ تارهای صوتی استفاده شده است.
صحبت پیوسته با بروزآوری این سه پارامتر به صورت پیوسته به اندازهی ۴۰ بار در ثانیه ترکیب شود. این راهکار برای یکی از کاربردهای تجاری دی.اس.پی که «صحبت و املا» نامیده میشود و یک وسیلهی الکترونیکی پرفروش برای بچههاست مناسب است. کیفیت صدای این نوع ترکیب کنندهی صحبت پایین است و بسیار مکانیکی و متفاوت با صدای انسان به نظر میرسد. ولی در هر صورت نرخ دادهی خیلی پایینی در حدود چند کیلوبیت بر ثانیه نیاز دارد.
همچنین این راهکار پایهای برای روش کدگذاری پیشگویانهی خطی (ال.پی.سی) ((Linear Predictive Coding [LPC])) در فشردهسازی صحبت فراهم میآورد. صحبت ضبط شدهی دیجیتالی انسان به تکههای کوچک تقسیم میشود و هر کدام با توجه به سه پارامتر مدل توصیف میشود. این عمل به طور معمول نیاز به یک دوجین بایت برای هر تکه دارد که نرخ دادهای برابر با ۲ تا ۶ کیلوبایت بر ثانیه را طلب میکند. این تکهی اطلاعاتی ارسال میشود و در صورت لزوم ذخیره میگردد و سپس توسط ترکیب کنندهی صحبت بازسازی میشود.
الگوریتمهای تشخیص صحبت با تلاش برای شناسایی الگوهای پارامترهای استخراج شده از این روش نیز پیشتر میروند. این روشها معمولاً شامل مقایسهی تکههای اطلاعاتی با قالبهای صدای از پیش ذخیره شده در تلاش برای تشخیص کلمات گفته شده میباشند. مشکلی که در اینجا وجود دارد این است که این روش همیشه به درستی کار نمیکند. این روش برای بعضی کاربردها قابل استفاده است اما با تواناییهای شنوندگان انسانی خیلی فاصله دارد.
۳- آیندهی فناوریهای پردازش صحبت
ارزش ایجاد فنآوریهای ترکیب و تشخیص صحبت بسیار زیاد است. صحبت سریعترین و کاراترین روش ارتباط انسانهاست. تشخیص صحبت پتانسیل جایگزینی نوشتن، تایپ، ورود صفحهکلید و کنترل الکترونیکی را که توسط کلیدها و دکمهها اعمال میشود را داراست و فقط نیاز به آن دارد که کمی برای پذیرش توسط بازار تجاری بهتر کار کند.
ترکیب صحبت علاوه بر آن که همانند تشخیص صحبت میتواند استفاده از کامپیوتر را برای کلیهی افراد ناتوان بدنی که دارای تواناییهای شنوایی و گفتاری مناسب هستند آسانتر سازد به عنوان یک وسیلهی خروجی کاربرپسند در محیطهای مختلف میتواند با جایگزین کردن بسیاری از علائم دیداری (انواع چراغها و…) و شنوایی (انواع زنگهای اخطار و …) با گفتارهای بیان کنندهی کامل پیامها استفاده از و رسیدگی به سیستمهای نیازمند این گونه پیامها را بهینه کند.
در اینجا لازم است به این نکته اشاره شود که پیشرفت در فنآوری تشخیص صحبت (و همچنین تشخیص گوینده) همان قدر که محدودهی دی.اس.پی را در بر میگیرد نیازمند دانش به دست آمده از محدودههای هوش مصنوعی و شبکههای عصبی است. شاید این تنوع دانشهای مورد نیاز به عنوان عامل دشواری مطالعهی مبحث پردازش صحبت در نظر گرفته شود حال آن که این گونه نیست و این تنوع راهکارها بخت رسیدن به سیستم با کارایی مطلوب را افزایش میدهد.
تواناییهای ابزارهایی که در بخش اول این فصل به آنها اشاره شد امیدواریهای فراوانی را در زمینهی موفقیت ابزارهای موجود فراهم میآورد و دامنهی وسیع شرکتها و مراکز دانشگاهی که در این زمینه فعالیت میکنند بر تنوع در قابلیتها و کاربردهای پیادهسازی شدهی این ابزارها میافزاید.
۴- منابع فصل
1- Steven W. Smith,The Scientist and Engineer’s Guide to Digital Signal Processing, Chapter 22: Audio Processing, from www.dspguide.com