
|
|
|
|
|
|
|
|
|
|
|
|
|
|
فصل هفتم روشهاي طراحي
سيستمهاي تشخيص گوينده 2- روشهاي مبتني بر چشمپوشي زماني پويا 3- روشهاي مبتني بر مدلهاي نهان ماركف 4- روشهاي مبتني بر مقدارگزيني برداري |
|
|
|
|
|
|
|
|
|
|
|
1-
مقدمه
همچنان كه پيش از اين
گفته شد سيستمهاي تشخيص گوينده در حالت كلي به دو نوع سيستمهاي تأييد هويت
گوينده[1]
و سيستمهاي بازشناسي گوينده[2]
تقسيم ميشوند. تفاوت اين دو سيستم در نحوة پذيرش ورودي است: در سيستمهاي نوع
اول گوينده با ارائة يك شناسه ادعاي هويت يك كاربر خاص را مينمايد حال آن كه در
سيستمهاي نوع دوم گوينده فقط عبارت عبور خود را بيان ميكند و سيستم او را از
بين تمامي كاربران خود تشخيص ميدهد. در فصل قبل در مورد
ساختار الگوهاي مورد بحث صحبت كرديم و متوجه شديم كه عمل مدلسازي سيگنال يا
استخراج خصيصهها[3] با حذف
ويژگيهاي بدون استفادة سيگنال صحبت و حفظ ويژگيهاي قابل استفاده براي بازشناسي
عبارات خاص الگوهايي را با ويژگيهاي انتخاب شده در اختيار ما قرار ميدهد. ساختارهايي كه براي هر
دو نوع سيستم ارائه شد هر دو داراي يك مرحله براي تشخيص ميزان شباهت الگوهاي
متعلق به گويندة حاضر با گويندة مورد ادعا (نوع اول) يا همة گويندگان است كه با
استفاده از آن معياري براي تصميم گيري در اختيار ما قرار داده ميشود. همچنان كه براي تشخيص
الگو الگوريتمهاي متعدد و روشهاي گوناگون وجود دارد الگوريتمهاي گوناگوني نيز
براي يافتن ميزان شباهت ميان الگوها وجود دارد كه انتخاب هر كدام از آنها بستگي
به ساختار سيستم مقصد دارد. انتخاب يك روش به
ويژگيهاي سيستم هدف بستگي دارد. بعضي از روشهاي موجود تنها ميتوانند فقط براي
سيستمهاي وابسته به متن[4]
يا فقط براي سيستمهاي مستقل از متن[5]
مورد استفاده قرار گيرند و بعضي ميتوانند براي هر دو نوع مورد استفاده قرار
گيرند. بحث اين فصل كه سه روش
عمدة يافتن ميزان شباهت الگوها را به صورت كلي مورد بحث قرار خواهد داد عملاُ
پيشزمينههاي نظري لازم براي طراحي سيستم هدف را كامل ميكند. 2-
روشهاي مبتني بر چشمپوشي زماني پويا[6]
اين روش كلاسيك براي
تشخيص خودكار گوينده در حالت وابسته به متن بر اساس يكسانسازي الگوها با
استفاده از الگوهاي طيفي[7]
يا روش طيفنگاره[8] استوار
است. در حالت كلي سيگنال صحبت به صورت يك دنباله از بردارهاي خصيصه[9]
كه رفتار سيگنال صحبت را براي يك گويندة خاص مشخص ميكند نمايش داده ميشود. يك
الگو ميتواند نمايشگر يك عبارت چند كلمهاي، يك كلمة منفرد، يك هجا يا يك صداي
ساده باشد. در روشهاي يكسانسازي
الگوها مقايسهاي بين الگوي عبارت ورودي و الگوي مرجع براي تشخيص هويت گوينده
انجام ميگيرد. يك جزء مهم در اين روشها بهنجارسازي تغييرات زماني هر آزمون تا آزمون
بعدي ميباشد. بهنجارسازي ميتواند با روش چشمپوشي زماني پويا صورت گيرد. اين
روش يك تابع بهينة توسيع/ فشردهسازي زماني را براي ايجاد صفبندي زماني غيرخطي
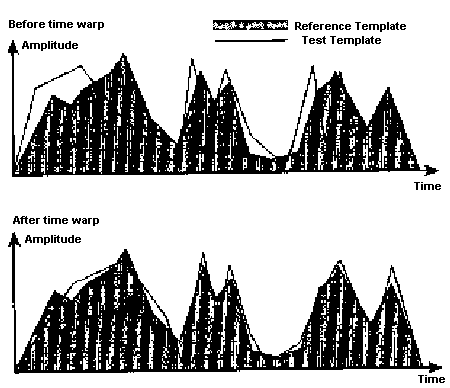
به كار ميگيرد. شكل 1 الگوها را پيش و پس از اعمال اين روش نشان ميدهد. به اين
نكته توجه شود كه چگونه چشمپوشي الگوهاي نمونة آزمون ميزان نزديكي دو الگو را
افزايش داده است:
شكل
شمارة 1 – نمونة يك الگو پيش و پس از اعمال روش چشمپوشي زماني پويا در شكل شمارة 1 فريمهاي
صحبت كه الگوهاي آزمون و مرجع را به وجود ميآورند به صورت مقادير دامنهاي
اسكالر بر روي نموداري كه محور افقي آن نشانگر زمان است نشان داده شدهاند.
بنابراين يك تابع تصميمگيري با جمعآوري اندازهگيريها بر حسب زمان ميتواند
محاسبه شود. در عمل الگوها بردارهاي چند بعدي هستند و فاصله بين آنها به صورت
فاصلة اقليدسي[10] مورد
محاسبه قرار ميگيرد. نوع ديگر فاصله كه براي مقايسة دو مجموعه از ضرايب
پيشگويانة خطي مورد استفاده قرار ميگيرد فاصلة ايتاكورا[11]
ميباشد. 3-
روشهاي مبتني بر مدلهاي نهان ماركف [12]
روشهاي مبتني برمدل
نهان ماركف جايگزينهايي براي روش يكسانسازي الگوها كه توسط روشهاي چشمپوشي
زماني پويا ارائه شد ميباشند كه مدلهاي احتمالي از سيگنال صحبت به وجود ميآورند
كه ويژگيهاي متغير با زمان آن را توصيف ميكند. يك مدل نهان ماركف يك فرايند
اتفاقي[13] دوگانه
براي ايجاد يك دنباله از نشانههاي مشاهده شده است. معناي دوگانه بودن اين
فرايند اتفاقي آن است كه اين فرايند داراي يك زيرفرايند اتفاقي ديگر است كه قابل
مشاهده نميباشد (از اينجا مفهوم عبارت نهان مشخص ميگردد) ولي ميتواند توسط
فرايند اتفاقي ديگري كه يك دنباله از مشاهدات را ايجاد ميكند مشاهده گردد. در
سيستمهاي نشخيص صحبت يا تشخيص گوينده دنبالة موقتي طيف صوتي ميتواند به صورت يك
زنجيرة ماركف[14] مدلسازي
شود تا روشي را كه يك صدا به صداي ديگري تبديل ميشود توصيف كند. اين عمل سيستم
را تا اندازة يك مدل كه قادر است فقط در يكي از يك تعداد متناهي از حالات متفاوت
باشد (به عنوان نمونه يك ماشين حالت متناهي[15])
كوچك ميكند. روشهاي مبتني بر مدل نهان ماركف ميتوانند هم در سيستمهاي وابسته
به متن و هم در سيستمهاي مستقل از متن مورد استفاده قرار گيرند. وقتي كه بعد از يك
انتقال حالت وارد يك حالت ديگر در ماشين حالت متناهي ميشويم يك نشانه از مجموعه
نشانههاي آن حالت به عنوان خروجي برگزيده ميشود. خروجي ميتواند يك تعداد
متناهي (روش مدل نهان ماركف گسسته) و يا يك مقدار پيوسته از خروجيها (روش توزيع
پيوسته) باشد. هر دو مدل به صورت مؤثر اطلاعات موقتي را مدلسازي ميكنند. سيستم
در بازههاي منظم زماني تغيير حالت ميدهد. حالتي كه مدل در هر آغاز هر بازة
زماني به آن ميرود به احتمالات بستگي دارد. تعدادي توپولوژي مدل كه
براي نمايش ماشين حالت متناهي استفاده ميشوند وجود دارند. يك ساختار معمول
ساختار چپ به راست است كه به آن مدل بكيس[16]
هم گفته ميشود و مثال آن نمونهاي است كه در شكل 2 نشان داده شده است. هر حالت
يك انتقال توقف[17]، يك
انتقال پيشرونده[18]
و يك انتقال جهشي[19]
دارد. با وجود آن كه دز شكل نشان داده نشده است احتمالهاي مختلفي به انتقالهاي
حالت متناهي وابستهاند و همچنين خروجي
هر حالت را كنترل ميكنند. نوع ديگر توپولوژي مدل نهان ماركف كه در اينجا نشان
داده نشده ساختار ارگوديك[20]
ميباشد كه در آن همانند يك شبكة كاملاُ متصل به هم هر حالت به همة ديگر حالات
داراي انتقال است.
شكل
شمارة 2 – مثالي از ساختار مدل نهان ماركف چپ به راست 4-
روشهاي مبتني بر مقدارگزيني برداري[21]
يك مجموعه از بردارهاي
خصيصة بازة كوتاه زماني يك گوينده كه براي آموزش سيستم به سيستم داده ميشوند ميتوانند
مستقيماً براي نمايش ويژگيهاي مهم عبارت ايراد شده توسط وي به كار گرفته شوند.
در هر صورت نتيجة كار آن است كه نيازمنديهاي حافظه براي ذخيرة دادهها و پيچيدگي
محاسباتي به سرعت با افزايش تعداد بردارهاي آموزش دهندة سيستم افزايش مييابد.
بنابراين يك نمايش مستقيم عملي نخواهد بود. مقدارگزيني برداري
اساساً روشي براي فشردهسازي دادههاي آموزش دهندة سيستم تا اندازهاي قابل
مديريت و كارا ميباشد. با استفاده از يك دفتر كد[22]
مقدارگزيني برداري كه شامل تعداد كمي بردارهاي خصيصه با نمايانگري بالاست ميتوان
دادههاي اوليه را به مجموعة كوچكي از نقاط نمايانگر كاهش داد. مقدارگزيني
برداري هم در سيستمهاي وابسته به متن و هم در سيستمهاي مستقل از متن قابل
استفاده است.
شكل
شمارة 3 – نمودار مفهومي كه شكلگيري يك دفتر كد مقدارگزيني برداري
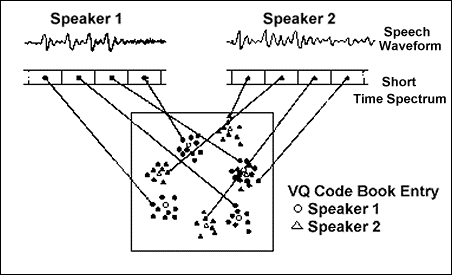
را به تصوير ميكشد شكل 3 يك نمودار مفهومي
را كه مثالي از شكلگيري يك دفتر كد مقدارگزيني برداري را به تصوير ميكشد نشان
ميدهد. يك گوينده ميتواند بر اساس مكان مركز ثقل بردارها از ديگري تشخيص داده
شود. در شكل 3 خصيصههاي طيفي زمان كوتاه با يك فضاي اقليدسي دوبعدي نشان داده
شدهاند. براي ايجاد يك مجموعه از نقاط گامهاي زير اجرا شدهاند: ·
از دو گوينده خواسته شده تا چند دنباله عبارت براي آموزش سيستم بيان
كنند. ·
دنبالههاي آموزش دهندة سيستم تحليل ميشوند و براي آموزش دفتر كد
مقدارگزيني برداري استفاده ميگردند. ·
سپس نقاط به بخشهاي جداگانه افراز ميگردند و دو دفتر كد توليد ميگردد
كه هر كدام چهار عنصر دارند. عناصر دفتر كد مقدارگزيني برداري به صورت دايره و
مثلث نمايش داده ميشوند و مركز ثقل بخشهاي مرتبط با فضاي خصيصة هر گوينده را
نشان مي دهند. همچنان كه در شكل 3
قابل مشاهده است با وجود كمي رويهمافتادگي دو دفتر كد هنوز كاملاُ مجزا هستند
و بنابراين هر گوينده ميتواند از ديگري تشخيص داده شود. هدف آموزش يك دفتر كد
مقدارگزيني برداري يافتن افرازهاي مناسب از يك فضاي برداري به صورت تعدادي ناحية
بدون رويهمافتادگي ميباشد. هر افراز با يك بردار مركز ثقل مرتبط نشان داده ميشود.
روشي معمول براي يافتن يك افرازبندي مناسب استفاده از يك روية بهينهسازي مانند
الگوريتم تعميميافتة لويد[23]
كه آشفتگي متوسط در بين بردارهاي آموزش سيستم و مركز ثقلها را كمينه ميكند ميباشد.
ساير روشها عبارتند از معيار كمترين بيشينه[24]
(كمينه كردن بيشترين آشفتگي) كه الگوريتم پوشش[25]
نيز ناميده ميشود و استفاده از قانون Kامين همساية نزديك[26]
به جاي قانون نزديكترين همسايه در محاسبة آشفتگي. 5-
مقايسة كارايي
آزمايشهاي گوناگوني
براي تعيين اين كه كدام روش براي تشخيص گوينده بهترين روش است صورت گرفته است و
مهم است كه به اين نكته توجه شود كه چگونه محققان مختلف در وضعيتهاي گوناگون به
نتايج متفاوتي دست پيدا نمودهاند. به عنوان نمونه اروين[27]
در نوشتار خود در ارتباط با آزمايشهايي كه وي در زمينة سيستمهاي وابسته به متن
براي مقايسة سه روش برشمرده شده انجام داده است به اين نتيجه رسيده است كه روش
مقدارگزيني برداري بهترين كارايي را ارائه ميكند. حال آن كه يو[28]،
ميسن[29]
و اگلبي[30] در مقالة
خود اشاره به اجراي آزمايشهايي مشابه نمودهاند كه نتايج متفاوتي را احراز نمودهاند.
نتيجة تجربة آنان كه در بردارندة آزمايشهايي براي سه روش توضيح داده شده براي
سيستمهاي وابسته به متن و دو روش متأخر براي سيستمهاي مستقل از متن است نمودار
شكل 4 براي سيستمهاي مستقل از متن و شكل 5 براي سيستمهاي مستقل از متن است.
همچنان كه در شكل 4 مشاهده ميشود بر اساس تجربيات اين گروه روش چشمپوشي زماني
پويا داراي بهترين كارايي است و همچنين روشهاي مدل نهان ماركف با چگالي پيوسته[31]
و مقدارگزيني برداري هشتعنصري استفاده شده به ازاي تعداد بردارهاي آموزش سيستم
متفاوت كاراييهاي متفاوت دارند:
شكل
شمارة 4 – درصد خطا بر اساس تعداد بردارهاي آموزش سيستم براي
روشهاي وابسته به متن چشمپوشي زماني پويا، مقدارگزيني برداري 8عنصري و مدل نهان
ماركف با چگالي پيوستة 8 حالتة 1 تركيبه همچنين از روي نمودار ميتوان
نتيجه گرفت كه با وجود آن كه براي تعداد بردارهاي آموزش كم روش چشمپوشي زماني
پويا عملكرد بهتري دارد با افزايش تعداد بردارها اين تفاوت عملكرد ديگر به صورت
واضح مشاهده نميشود. شكل شمارة 5 نتيجة
تجربيات اين گروه را براي سيستمهاي مستقل از متن نشان ميدهد: از
اين شكل اين گونه بر ميآيد كه روش مدل نهان ماركف با چگالي پيوسته نيازمند
تعداد بردارهاي آموزش سيستم بيشتري ميباشد.
شكل
شمارة 5 - درصد خطا بر اساس تعداد بردارهاي آموزش سيستم براي
روشهاي مستقل از متن مقدارگزيني برداري 32 عنصري و مدل نهان ماركف با چگالي
پيوستة تك حالتة 32 تركيبه ماتسوي[32]
و فروي[33] نيز
سيستمهاي مستقل از متن پيادهسازي شده با دو روش متأخر را مقايسه نمودند و اشاره
نمودهاند كه روش مدل نهان ماركف ارگوديك پيوسته در مقابل تغييرات عبارت پايداري
همساني با روش مقدارگزيني برداري دارد و عملكرد بسيار بهتري نسبت به روش مدل
نهان ماركف ارگوديك گسسته دارد. آنها همچنين به نتيجهاي مشابه با گروه قبلي دست
يافتهاند و آن اين است كه سيستمهاي مبتني بر روش مقدارگزيني برداري براي مقادير
كم داده پايدارتر از سيستمهاي مبتني بر روش مدل نهان ماركف پيوسته ميباشند. شكل
6 نتيجة تجربيات آنان را به تصوير ميكشد:
شكل
شمارة 6 – مقايسة سيستمهاي مستقل از متن (ماتسوي و فوروي 1992) 6-
منابع فصل
1)
Woon
Wei Kian and Yap Wei Wum, Approaches to Speaker Verification
Methods (Part of an article titled as Surprise 98 … reporting on
Speaker Verification), from http://www.iis.ee.ic.ac.uk/~frank/surp98/report/wwy2/approaches.htm |
|




|
|
|
|