این نشانی را با فایرفاکس مرور کنید (با کلیک کار نمیکند باید آن را به صورت دستی کپی کنید):
chrome://browser/content/browser.xul
انتظار دارم با چیزی در این مایهها مواجه شوید:
دلیلش را لابلای این نوشته میتوانید بیابید.
نوشتههای گاه و بیگاه حمیدرضا محمدی
این نشانی را با فایرفاکس مرور کنید (با کلیک کار نمیکند باید آن را به صورت دستی کپی کنید):
chrome://browser/content/browser.xul
انتظار دارم با چیزی در این مایهها مواجه شوید:
دلیلش را لابلای این نوشته میتوانید بیابید.
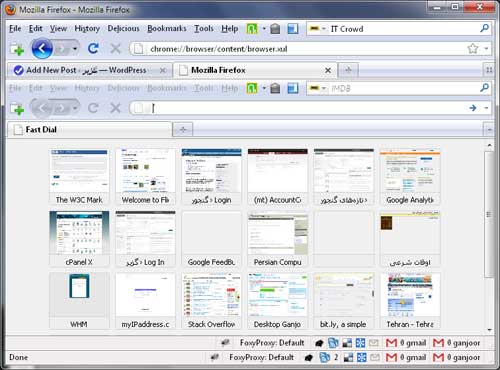
گفتگوی ایران صدا دربارهٔ گنجور که پیشتر خبرش را داده بودم هماکنون در آرشیو سایت ایران صدا در دسترس قرار گرفته است. علاوه بر آن که فرصت کافی برای طرح قسمت زیادی از مطالبی که آماده کرده بودم پیش نیامد مسألهٔ آزاردهندهٔ دیگر، تکرار پشت سر هم و بلاانقطاع عبارت «در واقع» در اول و وسط و آخر جملهها توسط من بود که در نوع خودش -فکر میکنم- تعجببرانگیز و رکوردشکن باشد. با عذرخواهی پیشاپیش بابت این درواقعباران اعصابخردکن غیرعمدی (و پساپس از دوستانی که به شکل زنده خود را در معرض آن قرار دادند، به ویژه مجری محترم برنامه و دستاندرکاران آن که مجبور به تحمل آن بودند) اگر احیاناً هنوز علاقمند بودید این گفتگو را بشنوید میتوانید با مراجعه به این صفحه و انتخاب بخش مربوطه (آیکون سبزرنگ متناظر با آن در تصویر زیر مشخص است) آن را به شکل آنلاین بشنوید.
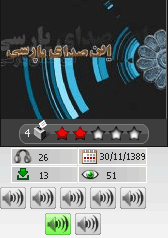
برای دریافت آن با سه کیفیت متفاوت نیز میتوانید از سمت چپترین گزینه در پایین این صفحه استفاده کنید.
لطفاً ببخشید!
چهارشنبه بیستم بهمن، ساعت ۱ بعدازظهر در برنامهٔ زندهٔ رادیو-تیوی اینترنتی ایرانصدا حضور خواهم داشت، موضوع بحث مرتبط با گنجور است. اینجا در این باره بیشتر بخوانید.
در ادامهٔ بحث نوشتهٔ پیشین در این نوشته به عنوان یک نمونهٔ عملی از نحوهٔ استفاده از رابط برنامهنویسی گنجور رومیزی، من قسمتی از یک فایل docx در دسترس از طریق سایت تصوف ایران -مربوط به اشعار وحدت کرمانشاهی- را به کمک تکه کدی که شرح آن در ادامه میآید به قالب گنجور رومیزی تبدیل کردهام (اصل فایل اینجاست، من آن را دریافت کردهام، با کمک ورد ۲۰۰۷ با پسوند docx ذخیره کرده و آن را در فایل زیپ پروژهٔ مربوط به این مطلب -قابل دریافت از این نشانی– گنجاندهام، بهروزآوری: پروژهٔ بهروز شده را میتوانید از گیتهاب دریافت کنید، از اینجا).
برای انجام این کار باید علاوه بر ویژوال استودیو (با امکان برنامهنویسی برای سکوی .NET ویرایش ۳.۵ یا ۴) کتابخانهٔ برنامهنویسی OpenXML را نیز نصب داشته باشید. این کتابخانه را از این صفحه دریافت و نصب کنید (OpenXMLSDKv2.msi با حجم کمتر از ۴ مگابایت برای مقصود مورد نظر ما کافیست، البته پیشنیاز نصب این کتابخانه سکوی .NET ویرایش ۳.۵ با سرویس پک ۱ است).
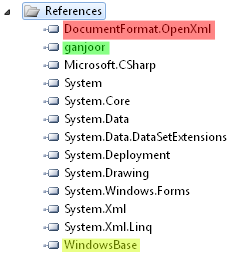
پس از نصب کتابخانهٔ یاد شده و ایجاد پروژه، ارجاع متناظر با آن را به فهرست ارجاعهای پروژه اضافه میکنیم تا فضاهای نام مورد نیاز در دسترس قرار گیرند.
برای پیادهسازی تبدیل مورد نظر لازم است الگوی تایپ فایل ورودی را استخراج کنیم. با بررسی ظاهر فایل ورودی الگوی عمومی زیر را مشاهده میکنیم:

بنابراین در ترتیب معمول بازخوانی محتوای این فایل (چگونه فایل تایپ شده): هر مصرع در تمام سلولهای حاوی متن از مصرعهای دیگر با یک break جدا شده است. محتوای سلول اول جدول (۱)، مربوط به مصرعهای اول ابیات است، بعد از این سلول، سلولی خالی داریم (۲)، محتوای سلول بعدی (۳) مربوط به مصرعهای دوم ابیات است، بعد یک سلول خالی (۴) (استثنایی وجود دارد که توضیح میدهم)، بعد سلولی شامل دو مصرع متوالی که مربوط به بیت تخلص شاعر است (۵) و پس از آن تا شعر بعدی یک سلول خالی دیگر داریم (۶).
پس ما در هنگام تبدیل فایل ورودی در هر لحظه انتظار یکی از سه نوع سلول جدول مصرعهای سمت راست، چپ یا وسط را میکشیم:
یکی از نکاتی که شاید به کار برنامهنویسانی بیاید که دوست دارند در گسترش دامنهٔ دادههای گنجور با استفاده از گنجور رومیزی مشارکت کنند این است که بدانند تنها راه تبدیل منابع اینترنتی یا فایلهای موجود به فرمت گنجور رومیزی کپی دستی اشعار از این منابع در ویرایشگر گنجور رومیزی نیست و میتوان با استفاده از C# یا هر یک از دیگر زبانهای .NET تقریباً به آسانی فایلهای مناسب برای نمایش در گنجور رومیزی را ساخت.
البته همانطور که احتمالاً این دسته از دوستان مطلعند فایلهای گنجور رومیزی در واقع پایگاه دادههای SQLite هستند و راه متداول برای ایجاد آنها به کمک زبانهای برنامهنویسی، استفاده از دستورات SQL است که نیازمند بازبینی ساختار پایگاه دادههای برنامه و به دست آوردن روابط بین جداول است. اما روشی که در این نوشته در مورد آن توضیح خواهم داد آسانتر است.
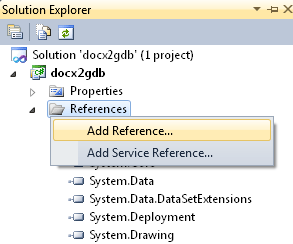
مقدمهٔ کار در ویژوال استودیو، اضافه کردن یک ارجاع به اسمبلی ganjoor.exe است (فایل اجرایی گنجور رومیزی که در مسیر نصب برنامه قرار دارد) تا فضای نام ganjoor در برنامه در دسترس قرار گیرد.*
[code lang=”c#”]
using ganjoor;
[/code]
پس از این کار به کلاس اصلی مدیریت دادهها در گنجور رومیزی که DbBrowser نام دارد دسترسی داریم. تکهکد زیر -که به نظرم به اندازهٔ کافی گویاست- نشان میدهد که چگونه میتوان با استفاده از این کلاس (و کلاسهای جانبی فضای نام ganjoor که اطلاعات دادهها را در خود دارند) یک فایل سادهٔ gdb یا s3db ساخت که گنجور رومیزی توانایی نمایش اطلاعات آن را دارد:

اخیراً دارند از فیلتر جیمیل هم عبور میکنند.
اگر دوست دارید آلبومهای تصاویر دیجیتالتان را بر اساس چهرهٔ افراد دستهبندی کرده، عکسهای خودتان یا دوستانتان را به سادگی یک کلیک غربال کنید ویندوز لایو فتوگالری ۲۰۱۱ را امتحان کنید.
پیرو نوشتهجات پیشین و جهت اطلاع معدود 😉 دوستانی که تازههای گنجور و صفحهٔ فیسبوک گنجور را دنبال نمیکنند ساغر (نرمافزار رایگان مرور اشعار فارسی با قابلیت اجرا تحت ویندوز، لینوکس و مک) منتشر شده است. جهت دریافت به این نشانی مراجعه کنید.

میدانید؟ اخیراً از جایی درخواست یک هدیه کردم (اینجا) و آن را تحویل گرفتم.
بد ندیدم، با یادکردی از آن لطف، با توجه به این که این روزها دست و دلم خیلی به کار نمیرود تقاضا(ها)یی بکنم برای کمک، شاید جیکوئریکاری پیدا شد ندای ما را لبیک گفت و از مشکلات گنجور کمی کم کرد. عموم تقاضاها -برای اهلش- به تخمین خودم چندان زمانبر نیست اما لطفی است بیحد در حق نه تنها من بلکه در حق تمام کسانی که با گنجور مشکلاتی از جنس آنچه شرح خواهم داد دارند.
اولین مشکل مربوط به اسکریپت جستجوی لغات با دوبار کلیک بر روی آنها در لغتنامهٔ دهخداست (اینجا را ببینید). مشکلش چیست؟ با کروم و سافاری و اپرا کار نمیکند. راهحلش چیست؟ تصور میکنم این باشد. اصلاً شاید خود همین باشد بدون نیاز به تغییر. کاری که شما باید برای من بکنید این است که مطمئن شوید با متون راست به چپ مشکلی ندارد، میشود اسکریپتهای لازمه را (از جمله کتابخانهٔ جیکوئری را) در ته صفحه قبل از بسته شدن تگ body (و نه در بالای صفحه) بارگذاری کرد و تمام. و البته، اگر مشکلی هست برایم رفعش کنید!
اما دومین و سومین مشکل را، اگر اولین مشکل را حل کردید، دنبالشان باشید: من اسکریپت سادهای برای شمارهگذاری ابیات در گنجور نوشتهام (اینجا را ببینید). این را برایم با جیکوئری بازنویسی کنید (اسکریپت را با بازبینی کد صفحات گنجور میبینید). مشکل سوم را البته اصراری روی حلش ندارم، احتمالاً سخت است ولی صورت مسألهاش این است که این مسأله را با استفاده از جیکوئری حل کنید.
نکتهٔ آخر که تصور میکنم از متن نوشته برداشت میشود ولی رک و راست گفتن آن خالی از فایده نیست آن که برای این مسائل من راهنمایی نمیخواهم، راهحل نهایی آمادهٔ نصب و صد در صد تضمینشده را میخواهم. گفتم که حواستان باشد اگر لطف میکنید ناقص نباشد!