دربارهٔ من:

آخرین نظردهندگان:
- Anonymous دربارهٔ تماشای ریحان
- لیام دربارهٔ @hrmoh
- سمانه ، م دربارهٔ @hrmoh
- M دربارهٔ شرح یک تجربه: سیانوژن روی گوشی LG Optimus 4X
- مسعود دربارهٔ @hrmoh
مشترک شوید:
ایمیل خود را در جعبهٔ زیر وارد کنید و دکمهٔ اشتراک را بزنید.
جستجو:
کپچا: «تو آدمی؟!»
۸۷/۱۰/۲۰ماشینهای صاحبنظر یک ضعف مهم دارند و احتمالاً راه حل شکست دادن آنها تکیه بر همین ضعف است. آن ضعف مهم آن است که آنها آدم نیستند! بله! آنها خیلی از تواناییهای یک انسان را ندارند. تواناییهای بسیاری از این روباتها محدود به پیدا کردن جعبههای متنی، تشخیص نوع دادهای که باید آنها را با آن پر کنند و ارسال خودکار دادههای هرز است. بنابراین میتوان با ملزم کردن کاربری که فرم را پر میکند (مثلاً در حال ثبت نام برای ایجاد یک حساب ایمیل است یا در حال نظر دادن در یک وبلاگ است) به انجام کاری که به طور طبیعی از عهدهی یک انسان برمیآید و از عهدهی یک روبات برنمیآید کاری کنیم که روباتها نتوانند فرمها را پرکنند. این اساس روشی برای مقابله با اسپمها در قلمرو فرمهای الکترونیکی است که «کپچا» (CAPTCHA سرواژهی حروف ابتدایی عبارتی انگلیسی با ترجمهی آزمایش تورینگ [نام شخصی است، با تست تورینگ دانشجویان نرمافزار آشنایی دارند] کاملاً خودکار عمومی برای جداسازی انسان از کامپیوتر) نامیده میشود.
«کپچای تصویر متن» متداولترین نوع کپچاست. نرمافزارهای ارسال اسپم معمولاً توانایی پردازش تصویرها را ندارند. آنها حداکثر میتوانند الگوهای سادهی متنی را پیدا کنند. پس ما اگر در هر بار نمایش فرم یک تصویر تصادفی به کاربر نشان دهیم و از او بخواهیم برای ما بگوید داخل آن تصویر چه میبیند، کاربران انسانی -چون توانایی پردازش تصویرها را دارند- میتوانند مسئلهی «چه چیزی داخل تصویر است» را به آسانی حل کنند و نرمافزار ارسال اسپم نه. سادهترین چیزی که داخل تصاویر میتوان گذاشت متون سادهی چند حرفی یا تک کلمهای است که با ترفندهایی همچون مخدوش کردن تصویر با خطوط، نویز و اعوجاج زمینه از حالت متن ساده خارج شده است. در ضمن چون نرمافزاری که این تصویر را ایجاد میکند جواب مسأله را میداند آزمایش درستی پاسخ کاربر هم کاری ندارد. این روش، اساس کپچای تصویر متن است که این روزها در خیلی از سایتها در انواع مختلف جلوی چشممان ظاهر میشود.

البته دستهای از کاربران انسانی هم هستند که به دلیل نابینایی توانایی حل کردن مسألهی کپچای تصویر متن را ندارند. برای حل مشکل این کاربران که معمولاً با کمک نرمافزارهای صفحهخوان (نرمافزاری است که با تکیه بر فناوری متن به صدا اتفاقات روی صفحهی کامپیوتر را برای کاربر شرح میدهد) از اینترنت استفاده میکنند در کنار کپچاهای تصویر متن، کپچاهای صوتی معادل نیز ایجاد شدند تا به این طریق مشکل این دسته از کاربران نیز حل شود.
راستی! تا حالا فکرش را کردهاید که تا به حال با چند کپچا برخورد کردهاید، چند تا از آنها را (به دلیل مخدوش بودن بیش از حد) نادرست جواب دادهاید و در مجموع چقدر وقت برای حل آنها تلف کردهاید؟! هر چند زمان تلف شده برای تک تک کاربران اینترنت احتمالاً ناچیز است، اما فکرش را بکنید که جمع زمانی که کل کاربران اینترنت برای حل کپچاها صرف میکنند چقدر است (البته احتمالاً در یکی از نوشتههایی بعدی از کسانی برایتان صحبت خواهم کرد که روزانه حداقل هشت ساعت کپچا حل میکنند!). واقعاً اگر اسپم نبود و اگر نرمافزارهای ارسال اسپم نبودند لازم نبود این سؤالهای احمقانه را پاسخ دهیم. جالب اینجاست که عدهای به همین موضوع فکر کردهاند و به ایدهای رسیدهاند که با استفاده از آن میتوان کاری کرد که حل کپچاها دیگر بیهوده نباشد و از آن سودی به همگان برسد.
مسألهای که حل کپچای تصویر متن به آن شباهت دارد او.سی.آر است. در این فرایند یک برنامهی کامپیوتری تلاش میکند تصویر اسکن شدهی متن را به متن قابل ویرایش یا جستجو تبدیل کند. اما درصد موفقیت نرمافزارها در تبدیل تصویر به متن همیشه بالا نیست. خیلی وقتها متن کاغذی مخدوش است یا کیفیت خوبی ندارد. بنابراین برنامهی او.سی.آر آن را با دقت خوبی نمیخواند، اما برنامه متوجه این قضیه میشود و میتواند قسمتهایی از متن را که خوب نخوانده جدا کند تا یک کاربر انسانی آنها را بازبینی و تأیید یا تصحیح کند. اما همیشه کاربران انسانی برای تصحیح خطاهای او.سی.آر در دسترس نیستند. مخصوصاً برای پروژههای عمومی تبدیل کتابهای کاغذی به متون دیجیتالی همیشه بودجهی کافی برای استخدام مصححان در دسترس نیست. سایتی به نام ریکپچا تلاش دارد با ارائهی سرویس کپچای رایگان، در کنار کلمات ایجاد شده توسط کامپیوتر -که پاسخ آنها برای نرمافزار کپچا مشخص است- کلماتی را که نرمافزارهای او.سی.آر «با دقت پایین» تشخیصشان دادهاند در دسترس کاربر انسانی قرار دهد و از او بخواهد درست آن را تایپ کند. به این ترتیب سایت یا سرویسی که از این روش استفاده میکند از کاربر میخواهد دو کلمه را وارد کند که جواب یکی را میداند و نتیجهی ورودی کاربر برای کلمهی دیگر را ذخیره میکند تا با دریافت چند جواب دیگر از کاربران دیگر راجع به متن آن اطمینان حاصل کند و نهایتاً دقت متون او.سی.آر شده را بالا ببرد. روش مشابهی نیز برای کپچاهای صوتی و تبدیل صداهای ضبط شدهی از دهههای گذشته به متن ارائه شده است.

در مورد انواع کپچا شاید این صفحه هم اطلاعات جدید و مفیدی داشته باشد.
فهرست سری نوشتههای من دربارهی هرزنامهها:
قسمت اول: ریشهی نام اسپم
قسمت دوم: هرزنامهها
قسمت سوم: کدامیک هرزنامههای بیشتری میگیرند: «علی» یا «زهرا»؟
قسمت چهارم: بگذارید «اسپم»ها را آنها بخورند!
قسمت پنجم: درآمدزایی هرزنامهها
قسمت ششم: ماشینهای صاحبنظر
قسمت هفتم: کپچا: «تو آدمی؟!»
قسمت هشتم: او.سی.آر: قاتل کپچای تصویر متن
قسمت نهم: صنعت حل کپچای هند و راهحلهای مقابله با اسپم با تکیه بر تحلیل محتوی
ماشینهای صاحبنظر
۸۷/۱۰/۰۶قلمرو ناخواستههای دنیای اینترنت محدود به نامههای الکترونیکی و هرزنامهها نیست. هر نوع فرم الکترونیکی که از طریق سایتهای اینترنتی در دسترس قرار میگیرد در معرض حملهی روباتها و برنامههای کامپیوتری است. این برنامهها با اهداف مختلف تلاش میکنند این فرمها را پر کنند و معمولاً حاصل این تلاشها انبوهی از نظرات هرز در وبلاگها، از کار افتادن کامپیوترهای میزبان سایتهای اینترنتی و انواع پیامدهای ناخوشایند دیگر است.
برای نمونه، هرزنامهنگاران میدانند که اکثر نرمافزارهای مبارزه با هرزنامهها، برای ایمیلهایی که از طریق سرویسهای محبوب ایمیل نظیر یاهو و جیمیل ارسال شده باشد اولویت خاصی قائلند و اگر ایمیل واقعاً از طریق این سرویسها ارسال شده باشد احتمال شناسایی آن به عنوان هرزنامه پایین میآید. اما از طرف دیگر همهی سرویسهای ایمیل محبوب سیستمهایی برای تشخیص استفادهی غیرمجاز کاربران دارند. به عنوان نمونه برخی از این سیستمها به محض این که تشخیص دهند یک کاربر در یک بازهی زمانی خاص تعداد زیادی ایمیل فرستاده حساب کاربری او را به عنوان هرزنامهنگار موقتاً مسدود میکنند. از این رو، هرزنامهنگاران سیستمهایی طراحی کردهاند که تلاش میکنند با پر کردن فرم ثبت نام سرویسهای ایمیل به صورت ماشینی حساب ایمیل بسازند و تا حد مسدود شدن با حساب ایجاد شده هرزنامه بفرستند و به محض مسدود شدن ایمیل، به سراغ ایمیل بعدی بروند!
نمونهی دیگر استفاده از فرمها برای ارسال اسپم، بخش نظرات وبلاگهاست. اسپمرها با استفاده از برنامههای کامپیوتری تلاش میکنند این فرمها را پر کنند و در قالب نظرهای وبلاگی به طور انبوه محصولات خود را تبلیغ کنند. انگیزههای دیگری نیز همچون افرایش لینکهای ورودی به سایت هدف و در نتیجه افزایش رتبهی سایت در موتورهای جستجو نیز در انتخاب این روش ارسال اسپم مؤثر است.
در نوشتهی بعدی به بعضی روشهای مقابله با اسپم در قلمرو فرمهای الکترونیکی اشاره خواهم کرد.
فهرست سری نوشتههای من دربارهی هرزنامهها:
قسمت اول: ریشهی نام اسپم
قسمت دوم: هرزنامهها
قسمت سوم: کدامیک هرزنامههای بیشتری میگیرند: «علی» یا «زهرا»؟
قسمت چهارم: بگذارید «اسپم»ها را آنها بخورند!
قسمت پنجم: درآمدزایی هرزنامهها
قسمت ششم: ماشینهای صاحبنظر
قسمت هفتم: کپچا: «تو آدمی؟!»
قسمت هشتم: او.سی.آر: قاتل کپچای تصویر متن
قسمت نهم: صنعت حل کپچای هند و راهحلهای مقابله با اسپم با تکیه بر تحلیل محتوی
بگذارید «اسپم»ها را آنها بخورند!
۸۷/۰۹/۰۷تولید فهرستهای تقریباً تصادفی از آدرسهای ایمیل -آن طور که در نوشتهی قبلی به آن اشاره کردم- هزینهی کاری و زمانی بالایی دارد و با توجه به آن که فقط درصدی از نشانیهای تولید شده معتبر هستند برای هرزنامهنگاران کوچک راهحل چندان بهصرفه و مفیدی نیست (البته، هرزنامهنگاران با یک ارسال آزمایشی و بررسی پاسخ دریافتی از سرورهای پست الکترونیکی، میتوانند ایمیلهای معتبر را غربال کنند و فهرست خودشان را بهبود دهند، ولی این کار هم هزینهی پردازشی بالایی دارد). راه حل بهتر، استفاده از فهرستهای ایمیلهای واقعی است. اما این فهرستها چگونه پر میشوند و اطلاعات آنها چگونه جمعآوری میشود؟ هرزنامهنگاران برنامههای کاربردی زیادی در اختیار دارند که به کمک آنها میتوانند فهرستهای خودشان را با ایمیلهای واقعی پر کنند. آنها برنامههایی در اختیار دارند که همانند رباتهای موتورهای جستجو به صفحات وب سرکشی میکنند و در آنها دنبال رشتههایی با الگوی نشانی پست الکترونیکی (نام@دامنه.پسوند دامنه) میگردند. پس یکی از اولین و بهترین راهها برای جلوگیری از اضافه شدن ایمیلتان به این فهرستها آن است که آن را در صفحات عمومی وب در اختیار بقیه نگذارید. سعی کنید به جای وارد کردن نشانی ایمیلتان در وبلاگ یا سایت شخصیتان صفحهی تماس بسازید و آن را طوری تنظیم کنید که پیام مخاطب را به طور غیرمستقیم به ایمیلتان بفرستد. بسیاری از سیستمهای نظرسنجی سایتها و وبلاگها از شما میخواهند که نام، نشانی وبسایت و ایمیلتان را وارد کنید. تا زمانی که مطمئن نشدهاید سیستم سایت یا وبلاگ مذکور ایمیل شما را به صورت عمومی منتشر نمیکند از وارد کردن ایمیلهای اصلیتان در این گونه کادرها خودداری کنید (به عنوان نمونه، یکی از سیستمهای پرطرفدار وبلاگنویسی وطنی که جهت حفظ حریم خصوصی نظردهندگان در وبلاگها آی.پی آنها را حتی در اختیار صاحب وبلاگی که نظر برای او گذاشته شده نمیگذارد -احتمالاً به دلیل این که حق همه است که ایمیل نظردهندگان را بدانند و ببینند- ایمیل نظردهندگان را به صورت عمومی منتشر میکند 😉 ). برخی از سایتها و تالارهای گفتگو بدون ثبتنام، مطالب و مقالات خود را در اختیار بازدیدکننده نمیگذارند و شما مجبورید برای دستیابی به مطلب مورد نظرتان در این گونه سایتها ثبتنام کنید. مشکل اینجاست که ثبتنام در این سایتها معمولاً دریافت نامههای ناخواسته را به دنبال دارد و علاوه بر این، برخی از این سایتها اطلاعات کاربران خود را در قالب فهرستهای ایمیل، به هرزنامهنگاران میفروشند. اگر تنها به یک مطلب یا مقاله از سایت یا تالار گفتگوی مورد نظر نیاز دارید بهتر است ابتدا سعی کنید با استفاده از سایتهایی مانند bugmenot.com اطلاعات ورود به اشتراکگذاشته شدهای از سایت مزبور بیابید و با استفاده از آن وارد سایت مورد نظر شوید (برای نمونه، چند نام کاربری و کلمهی عبور برای سایت آفتاب نقطه آر را اینجا ببینید). در صورتی که به نتیجه نرسیدید و مجبور شدید در سایت مورد نظرتان ثبتنام کنید به جای وارد کردن ایمیل واقعیتان از ایمیلهای یکبار مصرف استفاده کنید. سایتهایی نظیر www.mailinator.com بدون نیاز به ثبتنام، نشانیهای ایمیل موقتی در اختیارتان میگذارند که پس از پایان فرایندهای ثبتنام میتوانید با خیال راحت آنها را رها کنید و به قول صاحبان این سرویس: «بگذارید اسپمها را آنها بخورند»!
ادامه دارد …
فهرست سری نوشتههای من دربارهی هرزنامهها:
قسمت اول: ریشهی نام اسپم
قسمت دوم: هرزنامهها
قسمت سوم: کدامیک هرزنامههای بیشتری میگیرند: «علی» یا «زهرا»؟
قسمت چهارم: بگذارید «اسپم»ها را آنها بخورند!
قسمت پنجم: درآمدزایی هرزنامهها
قسمت ششم: ماشینهای صاحبنظر
قسمت هفتم: کپچا: «تو آدمی؟!»
قسمت هشتم: او.سی.آر: قاتل کپچای تصویر متن
قسمت نهم: صنعت حل کپچای هند و راهحلهای مقابله با اسپم با تکیه بر تحلیل محتوی
ریشهی نام اسپم
۸۷/۰۹/۰۳اگر به تبلیغات بالای پوشهی اسپم حساب جیمیلتان دقت کرده باشید، احتمالاً شما هم مثل من تا حالا متوجه شدهاید که بیشتر وقتها موضوع این تبلیغات به جای آن که دربارهی نرمافزارها و ابزارهای مقابله با اسپم یا به اصطلاح «هرزنامه»ها باشد، دربارهی خوراکیهاست!
در واقع واژهی «اسپم» پیش از آغاز عصر اینترنت نام تجاری نوعی غذای کنسرو شده بوده، که هم اکنون هم با همان نام تجاری (و البته بنا بر اصرار شرکت تولید کننده با صورت نوشتاری تماماً بزرگ (SPAM) برای متمایز بودن با اسپم اینترنتی و همچنین نشان دادن این که این نام یک نام اختصاری است) عرضه میشود و گویا بر خلاف هرزنامهها که همه جا ناخواستهاند خیلی هم خواستار دارد. در هر صورت ریشهی واژهی اسپم به معنی هرزنامه هم گویا، همان نام تجاری اسپم خوراکی است.

داستان انتخاب واژهی اسپم برای هرزنامههای الکترونیکی گویا از این قرار است که فراوانی «اسپم» در دوران جنگ جهانی دوم در اغذیهفروشیهای انگلستان -درست همان وقتی که به لحاظ شرایط جنگی خیلی از خوراکیهای گوشتی در این کشور مشمول جیرهبندی بودند الا «اسپم» که در همه جا پیدا میشد- دستمایهی داستان یکی از قسمتهای یک سریال کمدی دههی هفتاد میلادی شبکه تلویزیونی بی.بی.سی قرار گرفت، که در آن تکرار این واژه در منوی رستوران داستان آن قسمت از سریال و همچنین همراهی یک گروه همآواز جنبهی فراوانی این خوراکی را در آن زمان به طنز کشید. تحت تأثیر این سریال، بعدها و در آغاز دوران اینترنت، یکی از روشهای حالگیری افراد ناخواسته در اتاقهای گفتگو، پر کردن صفحات با واژهی SPAM بود و به همین دلیل اندک اندک واژهی «اسپم» به همه جور آشغال الکترونیکی ناخواسته از قبیل نامه، نظر وبلاگی و مانند آن که به صورت انبوه ارسال میشوند اطلاق شد (اصل ماجرا را در ویکیپدیای انگلیسی و در این قسمت بخوانید).
احتمالاً 😉 ادامه دارد …
فهرست سری نوشتههای من دربارهی هرزنامهها:
قسمت اول: ریشهی نام اسپم
قسمت دوم: هرزنامهها
قسمت سوم: کدامیک هرزنامههای بیشتری میگیرند: «علی» یا «زهرا»؟
قسمت چهارم: بگذارید «اسپم»ها را آنها بخورند!
قسمت پنجم: درآمدزایی هرزنامهها
قسمت ششم: ماشینهای صاحبنظر
قسمت هفتم: کپچا: «تو آدمی؟!»
قسمت هشتم: او.سی.آر: قاتل کپچای تصویر متن
قسمت نهم: صنعت حل کپچای هند و راهحلهای مقابله با اسپم با تکیه بر تحلیل محتوی
فارسیسازی افزونهی آلبوم عکس فلیکر
۸۷/۰۷/۱۸نسخههای جدید وردپرس (سیستم مدیریت محتوای وبلاگ من و میلیونها وبلاگ دیگر) امکان بروزرسانی خودکار افزونهها را فراهم کردهاند. اینطوری نیازی نیست برای بروز کردن افزونهها متوالیاً سایتهای نویسندههای آنها را چک کنید تا آخرین نسخهها را دریافت و نصب کنید. در هر صورت، برای ما -غیرانگلیسیزبانها- مشکلات ویژهای وجود دارد. مثلاً من تا پیش از این خیلی از افزونهها را با روشهای غیراستاندارد -ویرایش کد اصلی- فارسی کرده بودم تا آن را با حال و هوای وبلاگم وفق بدهم. مسألهای که این روش فارسی کردن به وجود میآورد آن است که با بروزرسانی خودکار تغییرات اعمال شده را از دست میدهم. بنابراین روش بهتر آن است که از امکاناتی که بسیاری از افزونهها برای ترجمه به زبانهای مختلف فراهم میآورند استفاده کنیم.
افزونهی آلبوم عکس فلیکر برای وردپرس از جمله همین افزونههایی بوده که تا به حال، من به شیوهی غیراستاندارد آن را ترجمه کرده بودم و معمولاً با مرارت زیاد آن را بروز میکردم (این افزونه همانی است که آلبوم عکس وبلاگ من به کمک آن کار میکند). چند وقت پیش خالق این افزونه اعلام کرد که قصد دارد پشتیبانی از زبانهای مختلف را به این افزونه اضافه کند. این شد، که تصمیم گرفتم به عنوان حداقل کاری در مقام قدرشناسی میشود در مورد آدمهایی که وقت خودشان را برای تولید ابزارهای رایگان صرف میکنند انجام داد، یک ترجمهی فارسی برای افزونه اضافه کنم. یک ترجمهی اولیه -که خالی از اشکال نبود- آماده کردم و برای نویسندهی افزونه فرستادم که او این ترجمه را در آخرین نسخهی افزونه گنجانده است (تصویری از ترجمهی فارسی افزونه در محیط وردپرس فارسی را هم گذاشته توی وبلاگش، اینجا). در هر صورت ترجمه نیاز به بازبینی دارد، اگر از این افزونه استفاده میکنید و دوست دارید نسخههای فارسی آن بروز باشد سری به این نشانی بزنید و ترجمهها را بازبینی کنید، نویسندهی افزونه آخرین ترجمهها را از همانجا بر میدارد. من با این سایتی که امکان ترجمه را در اختیار میگذارد مشکلات زیادی دارم که احتمالاً یا ناشی از فیلترینگ است یا ناشی از تحریم، در هر صورت بازبینی ترجمهها برایم کمی سخت است ولی سعی خودم را میکنم تا اشکالات ترجمه را -اگر کسی پیدا نشد که زحمتش را بکشد- خودم حل کنم.
در دست تعمیر
۸۷/۰۵/۰۳این عکس را به این دو تا اضافه میکنم:
توضیح بیشتر: این پیام «در دست تعمیر»، مربوط به سایت کوکامنت است که قبلاً دربارهی آن مطلبی نوشتهام (اینجا).
مطالعه به شیوهی آمازون
۸۶/۰۸/۲۸آمازون سایتی که بیشتر ما آن را با فروشگاه آنلاین بیرقیب کتاب و محصولات فرهنگیش 😉 میشناسیم طی سالهای اخیر محصولات و خدمات جالبی را به مجموعهی تحت مالکیتش اضافه کرده. سرویس ترک مکانیکی (برای خودکارسازی به کارگیری توانمندیهای انسانی در حل مسائل یا انجام کارهایی که هنوز ماشینها هوشمندی یا سرعت مناسب جهت حل یا پردازش آنها را ندارند) و سرویس فضای آنلاین S3 از جملهی این خدمات هستند که نشان از سرمایهگذاری و برنامهریزی هوشمندانهی این شرکت دارند.
این روزها آمازون در آستانهی عرضهی یک محصول سخت افزاری است با نام آمازون کیندل که از لحاظ نوع عملکرد و روش استفاده مشابهتهای زیادی با محصولی دارد که سونی در سال گذشته عرضه کرد (اینجا را ببینید): یک «کتابخوان الکترونیکی» که صفحهی نمایش (گویا سیاه و سفید) آن به گونهای طراحی شده که بیشتر شبیه کاغذ چاپی به نظر برسد. اما در عین حال تفاوت مهم این وسیله با محصول سونی آن است که آمازون یک شبکهی انتقال دادههای بیسیم گسترده برای کاربران این محصول طراحی کرده تا بتوانند فارغ از هزینههای پهنای باند و شبکهی بیسیم از طریق خدمات این شرکت اقدام به خرید کتاب کنند، مشترک روزنامهها و مجلات شوند و همچنین به وبلاگهای پرطرفدار و دائرﺓالمعارف ویکیپدیا دسترسی داشته باشند.
اگر سرعت اینترتتان اجازه میدهد توصیه میکنم دموی این محصول را از نظر بگذرانید یا آن را از اینجا دریافت کنید (حجم فایل تقریباً هفده مگابایت).

سن؟!
۸۶/۰۵/۱۴متیو مولنوگ پایهگذار سیستم مدیریت وبلاگ وردپرس هماکنون ۲۳ سال دارد.
بلیک راس یکی از دو پایهگذار مرورگر فایرفاکس هماکنون ۲۲ سال دارد. او کار خود را بر روی این مرورگر از ۱۵ سالگی آغاز کرده است.
کریستوفر تیت پدیدآورندهی سرویس اشتراک عکس زوومر در ۱۷ سالگی اولین نگارش این سرویس را آماده و عرضه کرد.
علیرضا عسکری سرویس وبلاگنویسی فارسی میهن بلاگ را در ۱۶ سالگی پایهگذاری کرده.
…
«چقدر» جالب؟!
۸۶/۰۳/۲۵(۱)
لرد کلوین گفته:
شما در صورتی میتوانید ادعا کنید در مورد چیزی دانش و آگاهی دارید که بتوانید آن را اندازه گرفته، در قالب اعداد بیان کنید!
این ادعا اغراقآمیز به نظر میرسد اما تلاش برای تحقق آن مفید است.
مثلاً فرض کنید نمایههای کوچکی از تعداد زیادی عکس با موضوعات یکسان را گذاشتهایم بغلدست هم و در یک صفحه جمع کردهایم و بینندگان میتوانند با کلیک بر روی نمایهی هر عکس آن را با اندازهی بزرگتر مشاهده کنند. اگر این صفحه روی اینترنت قرار گیرد و تعداد زیادی بازدیدکننده داشته باشد مشخص میشود که بعضی از عکسها به نسبت بقیه از نظر بازدیدکنندگان جالبتر هستند. «جالبتر» به این معنا که این عکسها نظر تعداد بیشتری از بازدیدکنندگان را به خود جلب میکنند و بنابراین تعداد بیشتری از بینندگان این عکسهای جالبتر را برای دیدن با اندازهی بزرگتر انتخاب میکنند. حالا اگر ما بتوانیم میزان جالب بودن عکسها را حساب کنیم و آن را با عدد و رقم بیان کنیم میتوانیم عکسها را به ترتیب میزان جالب بودن برای بینندگان مرتب کنیم تا تجربهی مفرحتری برای آنها فراهم آوریم. مسئلهی مهم اینجاست که بدانیم برخلاف آنچه ممکن است از مثال من برداشت شود «جالبتر بودن» با «پربازدیدکنندهتر بودن» متفاوت است. در واقع جالب بودن یک عکس میتواند باعث بیشتر دیده شدن آن شود اما اگر عکسی بیشتر دیده میشود لزوماً دلیل خیلی قاطعی وجود ندارد که از عکسهای دیگر جالبتر باشد. مثلاً ممکن است این عکس مدت زمان بیشتری در دید قرار گرفته باشد یا علت توجه به آن ارجاع از سایتها و صفحات وب پربازدیدکننده باشد یا حتی مثلاً جای آن در صفحه باعث بیشتر دیده شدن آن شود. معیار «جالب بودن» زمانی برای ما ارزش پیدا میکند که بتوانیم با تحلیل رفتار یک نمونهی آماری از بازدیدکنندگان برای آن «عددی» -فارغ از عمر عکسها، موضوع و سایر ویژگیهای آنها- به دست آوریم که بر طبق آن بتوانیم رفتار بازدیدکنندگان را در قبال یک عکس خاص در مقایسه با عکسهای دیگر پیشبینی کنیم.

این تقریباً همان چیزی است که فلیکر با ارائهی کمیتی به نام «جالب بودن» به دنبال آن است.
یکی از پربازدیدکنندهترین صفحات فلیکر صفحهی اکسپلور آن است. در این صفحه عکسهایی که در طی روز جاری روی فلیکر قرار گرفتهاند و از نظر فرمولهای فلیکر «جالبترین» هستند در دسترس قرار میگیرند. علاوه بر آن میتوان از طریق همین صفحه به «جالبترین»های روزهای قبل هم دسترسی پیدا کرد. جالب اینجاست که بایگانی جالبترینها همیشه دستخوش تحول است و رفتار بینندگان در طول زمان باعث میشود رتبهی عکسها در این بایگانی بالا و پایین برود.
(۲)
الگوریتمها و فرمولهایی که فلیکر برای تعیین میزان جالب بودن عکسها به کار میگیرد تا حدود زیادی سلیقهای هستند و در طول زمان هم تغییر میکنند. این مسئله باعث میشود درک چگونگی عملکرد این الگوریتمها مشکل باشد. چندی پیش یکی از کاربران ایرانی شناخته شده و حرفهای فلیکر تلاش کرد تا با ترغیب دوستان و آشنایان خود به علامت زدن یک عکس به عنوان «عکس مورد علاقه»، نظر دادن در مورد آن، برچسب گذاشتن روی آن و کارهایی مثل این عملکرد این الگوریتم را مورد تحلیل قرار دهد. عکس مورد نظر علی رغم این تلاشها به صفحهی جالبترینهای فلیکر منتقل نشد. آزمایش این کاربر ایرانی نشان داد که الگوریتمهای فلیکر تا حدود زیادی در برابر عملکردهای این شکلی مقاومند و پارامترهای مهم دیگری را غیر از حجم رجوع به یک عکس در فرمولهایشان دخیل میکنند (پی نوشت: حتی ممکن است به صورت دستی نتایج این الگوریتمها تغییر کند، برای کسب اطلاعات بیشتر نوشتههای پای عکس مذکور را بخوانید و لینکها را دنبال کنید).
(۳)
اگر طی دیروز و امروز به صفحهی جالبترینهای فلیکر مراجعه کرده باشید به احتمال بسیار زیاد عکسهایی را دیدهاید که در آنها به رویهی فلیکر در سانسور بعضی عکسها در بعضی کشورها اعتراض شده:
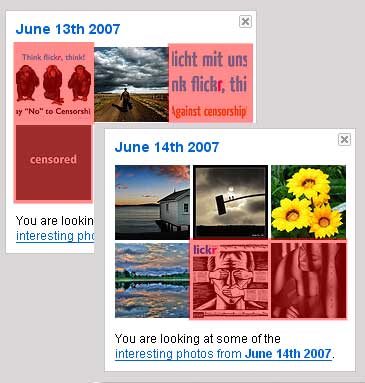
فلیکر اخیراً عکسهای با محتوای نامناسب (برهنگی و مانند آن) را علامت میزند و در صورتی که تنظیمات کاربر نشان دهد که این جور عکسها نباید برای او نشان داده شوند آنها را در دسترس او قرار نمیدهد. این تنظیمات میتواند توسط خود کاربر تغییر داده شود مگر آن که مشخص شود که کاربر تبعهی یکی از کشورهای آلمان، هنگ کنگ، کره یا سنگاپور است. در این صورت (حدس میکنم البته) به لحاظ محدودیتهای قانونی این کشورها این جور عکسها حتی علی رغم خواستهی خود کاربر در دسترس او قرار نمیگیرند. عکسهای اعتراضآمیز فوقالذکر این رویهی فلیکر را مورد انتقاد قرار دادهاند و تلاش میکنند فلیکر را وادار کنند در مورد این رفتارش «بیشتر فکر کند»!

صاحبان این عکسهای اعتراضآمیز در این نمونه ثابت کردهاند که الگوریتمهای فلیکر برای یافتن جالبترینها خیلی هم ضدگلوله نیستند و میشود رفتار آنها را کنترل کرد به گونهای که حتی علیه فلیکر رفتار کنند و به آن اعتراض کنند.
پی نوشت: انگار قبلاً هم در این مورد نوشتهام!
ابزارهای گوگل برای گردانندگان سایتها
۸۶/۰۱/۱۷این گوگل وب مستر تولز یا همان گوگل سایت مپس قدیمی خودمان سرویس مفید و جالبی است. علاوه بر آن که کمک میکند به این که سایتتان بهتر در گوگل ایندکس بشود، یک سری کنترلهای جالبی هم روی نحوهی ایندکس شدن سایت در اختیار مالکش میگذارد. اطلاعات جالبی هم میدهد. مثلاً من که به خاطر برخی مشکلات اخیرم به قضیهی ترافیک و پهنای باند علاقمند شدهام امروز این اطلاعات جالب را راجع به پهنای باندی که روزانه گوگل از سایت من مصرف میکند پیدا کردم:
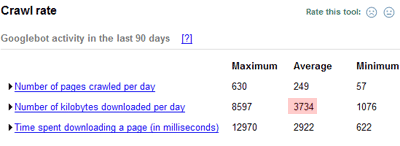
این نشان میدهد که گوگل (در حال حاضر) به طور متوسط ماهیانه صد و خردهای مگابایت از پهنای باند من را مصرف میکند.
اشاره: وبلاگهای مبتنی بر وردپرس میتوانند پس از تکمیل مراحل ثبت نام در این سرویس به کمک این افزونه از امکانات آن بهرهمند شوند.