این نوشته را به این صفحه منتقل کردم.
Category: برنامهنویسی
رابط برنامهنویسی گنجور رومیزی – بخش دوم
در ادامهٔ بحث نوشتهٔ پیشین در این نوشته به عنوان یک نمونهٔ عملی از نحوهٔ استفاده از رابط برنامهنویسی گنجور رومیزی، من قسمتی از یک فایل docx در دسترس از طریق سایت تصوف ایران -مربوط به اشعار وحدت کرمانشاهی- را به کمک تکه کدی که شرح آن در ادامه میآید به قالب گنجور رومیزی تبدیل کردهام (اصل فایل اینجاست، من آن را دریافت کردهام، با کمک ورد ۲۰۰۷ با پسوند docx ذخیره کرده و آن را در فایل زیپ پروژهٔ مربوط به این مطلب -قابل دریافت از این نشانی– گنجاندهام، بهروزآوری: پروژهٔ بهروز شده را میتوانید از گیتهاب دریافت کنید، از اینجا).
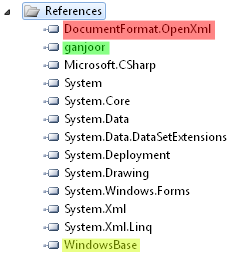
برای انجام این کار باید علاوه بر ویژوال استودیو (با امکان برنامهنویسی برای سکوی .NET ویرایش ۳.۵ یا ۴) کتابخانهٔ برنامهنویسی OpenXML را نیز نصب داشته باشید. این کتابخانه را از این صفحه دریافت و نصب کنید (OpenXMLSDKv2.msi با حجم کمتر از ۴ مگابایت برای مقصود مورد نظر ما کافیست، البته پیشنیاز نصب این کتابخانه سکوی .NET ویرایش ۳.۵ با سرویس پک ۱ است).
پس از نصب کتابخانهٔ یاد شده و ایجاد پروژه، ارجاع متناظر با آن را به فهرست ارجاعهای پروژه اضافه میکنیم تا فضاهای نام مورد نیاز در دسترس قرار گیرند.
برای پیادهسازی تبدیل مورد نظر لازم است الگوی تایپ فایل ورودی را استخراج کنیم. با بررسی ظاهر فایل ورودی الگوی عمومی زیر را مشاهده میکنیم:

بنابراین در ترتیب معمول بازخوانی محتوای این فایل (چگونه فایل تایپ شده): هر مصرع در تمام سلولهای حاوی متن از مصرعهای دیگر با یک break جدا شده است. محتوای سلول اول جدول (۱)، مربوط به مصرعهای اول ابیات است، بعد از این سلول، سلولی خالی داریم (۲)، محتوای سلول بعدی (۳) مربوط به مصرعهای دوم ابیات است، بعد یک سلول خالی (۴) (استثنایی وجود دارد که توضیح میدهم)، بعد سلولی شامل دو مصرع متوالی که مربوط به بیت تخلص شاعر است (۵) و پس از آن تا شعر بعدی یک سلول خالی دیگر داریم (۶).
پس ما در هنگام تبدیل فایل ورودی در هر لحظه انتظار یکی از سه نوع سلول جدول مصرعهای سمت راست، چپ یا وسط را میکشیم:
رابط برنامهنویسی گنجور رومیزی – بخش اول
یکی از نکاتی که شاید به کار برنامهنویسانی بیاید که دوست دارند در گسترش دامنهٔ دادههای گنجور با استفاده از گنجور رومیزی مشارکت کنند این است که بدانند تنها راه تبدیل منابع اینترنتی یا فایلهای موجود به فرمت گنجور رومیزی کپی دستی اشعار از این منابع در ویرایشگر گنجور رومیزی نیست و میتوان با استفاده از C# یا هر یک از دیگر زبانهای .NET تقریباً به آسانی فایلهای مناسب برای نمایش در گنجور رومیزی را ساخت.
البته همانطور که احتمالاً این دسته از دوستان مطلعند فایلهای گنجور رومیزی در واقع پایگاه دادههای SQLite هستند و راه متداول برای ایجاد آنها به کمک زبانهای برنامهنویسی، استفاده از دستورات SQL است که نیازمند بازبینی ساختار پایگاه دادههای برنامه و به دست آوردن روابط بین جداول است. اما روشی که در این نوشته در مورد آن توضیح خواهم داد آسانتر است.
مقدمهٔ کار در ویژوال استودیو، اضافه کردن یک ارجاع به اسمبلی ganjoor.exe است (فایل اجرایی گنجور رومیزی که در مسیر نصب برنامه قرار دارد) تا فضای نام ganjoor در برنامه در دسترس قرار گیرد.*
[code lang=”c#”]
using ganjoor;
[/code]
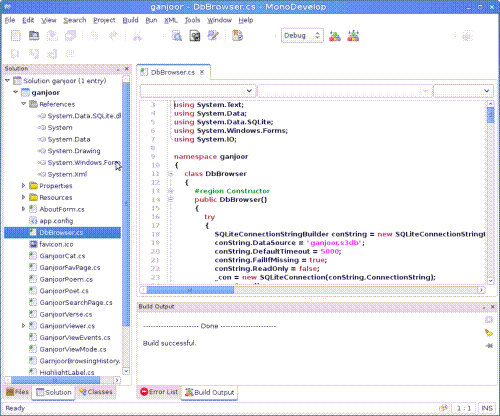
پس از این کار به کلاس اصلی مدیریت دادهها در گنجور رومیزی که DbBrowser نام دارد دسترسی داریم. تکهکد زیر -که به نظرم به اندازهٔ کافی گویاست- نشان میدهد که چگونه میتوان با استفاده از این کلاس (و کلاسهای جانبی فضای نام ganjoor که اطلاعات دادهها را در خود دارند) یک فایل سادهٔ gdb یا s3db ساخت که گنجور رومیزی توانایی نمایش اطلاعات آن را دارد:
یاریگری هست؟
میدانید؟ اخیراً از جایی درخواست یک هدیه کردم (اینجا) و آن را تحویل گرفتم.
بد ندیدم، با یادکردی از آن لطف، با توجه به این که این روزها دست و دلم خیلی به کار نمیرود تقاضا(ها)یی بکنم برای کمک، شاید جیکوئریکاری پیدا شد ندای ما را لبیک گفت و از مشکلات گنجور کمی کم کرد. عموم تقاضاها -برای اهلش- به تخمین خودم چندان زمانبر نیست اما لطفی است بیحد در حق نه تنها من بلکه در حق تمام کسانی که با گنجور مشکلاتی از جنس آنچه شرح خواهم داد دارند.
اولین مشکل مربوط به اسکریپت جستجوی لغات با دوبار کلیک بر روی آنها در لغتنامهٔ دهخداست (اینجا را ببینید). مشکلش چیست؟ با کروم و سافاری و اپرا کار نمیکند. راهحلش چیست؟ تصور میکنم این باشد. اصلاً شاید خود همین باشد بدون نیاز به تغییر. کاری که شما باید برای من بکنید این است که مطمئن شوید با متون راست به چپ مشکلی ندارد، میشود اسکریپتهای لازمه را (از جمله کتابخانهٔ جیکوئری را) در ته صفحه قبل از بسته شدن تگ body (و نه در بالای صفحه) بارگذاری کرد و تمام. و البته، اگر مشکلی هست برایم رفعش کنید!
اما دومین و سومین مشکل را، اگر اولین مشکل را حل کردید، دنبالشان باشید: من اسکریپت سادهای برای شمارهگذاری ابیات در گنجور نوشتهام (اینجا را ببینید). این را برایم با جیکوئری بازنویسی کنید (اسکریپت را با بازبینی کد صفحات گنجور میبینید). مشکل سوم را البته اصراری روی حلش ندارم، احتمالاً سخت است ولی صورت مسألهاش این است که این مسأله را با استفاده از جیکوئری حل کنید.
نکتهٔ آخر که تصور میکنم از متن نوشته برداشت میشود ولی رک و راست گفتن آن خالی از فایده نیست آن که برای این مسائل من راهنمایی نمیخواهم، راهحل نهایی آمادهٔ نصب و صد در صد تضمینشده را میخواهم. گفتم که حواستان باشد اگر لطف میکنید ناقص نباشد!
داستانهایی دربارهٔ اعداد تصادفی
۱) تابع تولید عدد تصادفی

۲) چرخ چهارگوش
برنامهنویس سرشناسی که همچون من و احتمالاً شما، آن روزها که قرار بود موزیلا ویرایش ۳.۵ از مرورگر محبوبش را منتشر کند ذوق دریافت فایرفاکس جدید را داشت در روزهای اول استفاده از این ویرایش مهم فایرفاکس به مشکل آزاردهندهای برخورد کرد:
پس دست به کار شدم و نصاب فایرفاکس را در روز انتشار دریافت کردم و پس از گذر از کثیفکاری معمول بهروزرسانی افزونهها توانستم مرورگر جدید را برای اولین بار اجرا کنم و خدایا من چه میبینم: وب -انگارکن- به سال ۱۹۹۴ برگشته: وقتی که هیچ کس جز خورههای واقعی سایت نداشت و همه چیز به سرعت برق بود. زندگی شیرین شده بود!
روز بعد با فنجان قهوهٔ تازه در دست، فایرفاکس ۳.۵ عزیزم را روی سیستم تازه بالا آمدهام اجرا کردم. انتظار داشتم پنجرهٔ مرورگر را در عرض چند ثانیه ببینم تا باز هم وبگردی با سرعت برقآسا را تجربه کنم، اما اتفاقی نیفتاد. البته، یک اتفاق افتاد، هارد دیسک کامپیوترم مثل وقتهایی که آن را ویروسیابی میکنم مشغول شده بود تا این که بعد از ۳۵ ثانیه یا چیزی در همین حدود بالاخره توانست تمام بیتها و تکههای لازم را پیدا کند و چهرهٔ آشنای فایرفاکس را به من نشان بدهد تا من راهم را به دنیای بیرون شروع کنم!
فایرفاکس روی سیستم فرد معلومالحال یاد شده همچنان سریع کار میکرد اما همیشه شروع شدنهایش کند و آزاردهنده بود. تا این که بالاخره تصمیم گرفت با جستجو در انجمنهای پشتیبانی فایرفاکس ریشهٔ مشکل را بیابد و این جستجو به کشف این نکته این انجامید که آقا، در این مصیبت تنها نیست و همدردهای زیادی دارد. بگذریم، خلاصه آن که مشخص شد مشکل مربوط به کتابخانهٔ NSS است. کتابخانهای شامل توابع امنیت شبکه که انواع کارکردهای رمزنگاری و امنیتی را پوشش میدهد و برای پیادهسازی این توابع نیاز به اعداد تصادفی دارد:
ایجاد اعداد تصادفی واقعی مشکل است چرا که در یک سیستم کامپیوتری هیچ چیز واقعاً تصادفی نیست: هر چیزی نتیجهٔ یک عمل قابل پیشبینی است. پسران و دختران باهوش تیم NSS باید این مسأله را به گونهای حل میکردند: چطور اعداد تصادفی واقعی ایجاد کنیم که تا حد ممکن تصادفی باشند؟ به جای استفاده از توابع ارائه شده توسط سیستم عامل (که این قابلیت را به دلیل نیاز پروتکل TCP در خود دارد) آنها این کار را به همان شیوهای که عموماً شرکت موزیلا کارهایش را انجان میدهد انجام دادند: چرخ را از نو اختراع کردند. من مشکلی با اختراع مجدد چیزها ندارم، اشتباه برداشت نکنید، هیچ چرخی مثل چرخ دیگر نیست. اگر چه، مشکل اختراع دیگربارهٔ چرخ آن است که علاوه بر آن که در این فرایند شما حق اشتباه کردن ندارید، باید چرخی بسازید که از چرخهای اختراع شدهٔ قبلی بهتر باشد. برای نمونه هیچ کس از چرخ چهارگوش شما استفاده نخواهد کرد.
برای حل مشکل اعداد تصادفی، تیم NSS به روشی هوشمندانه روی آورده بودند، رویکردی چنان عالی که تا به حال به ذهن هیچ کس نرسیده بود: آنها تصمیم گرفتند که تمام فایلهای موجود در تمام پوشههای موقتی ویندوز را با چند ریسمان موازی بخوانند تا از آنها به عنوان نقطههای آغاز (seed) تولید اعداد تصادفی استفاده کنند! توجه کنید: این پوشهها در هر چند میلیثانیه تغییر میکنند، به سرعت در دسترسند، تأخیری در دسترسی به آنها وجود ندارد و هیچوقت با چیزهای حاشیهای به دردنخور پر نمیشوند!
البته، پاراگراف بالا ذهنیت تیم NSS بود. در دنیای واقعی، چیزها یک کوچولو متفاوتند. متوجه هستید که؛ فایرفاکس ویرایش ۳.۵ کش اینترنت اکسپلورر را و پوشهٔ temp ویندوز برای پروفایل کاربر را توسط زیرسیستم NSS خود میخواند. این نه تنها به نظر من یک نباید به جهت خواندن دادههای موقتی برنامهٔ دیگر است، بلکه یک بیتوجهی شگفتآور نسبت به گلوگاه اصلی کامپیوترهای امروزی است: هارد دیسکها. اگر شما ویروسکشی داشته باشید که در حالت بددلانه تنظیم شده باشد پیمایش پوشههای موقت توسط NSS کندتر هم خواهد بود چرا که دسترسی به هر فایل از سوی فایرفاکس باعث اسکن آن توسط ویروسکش میشود. و اگر کاربر، با کامپیوترش هیچ کاری غیر از مرور وب با فایرفاکس نکند به گونهای که این پوشههای موقت دستنخورده یا خالی بمانند، آن وقت چه؟ آیا خواندن فایل بدترین روش ممکن برای تولید نقطههای آغاز اعداد تصادفی نیست؟
۳) ماشین تولید اعداد تصادفی

– مطمئنید که این تصادفی است؟
– مشکل تصادفی بودن همین است که هیچ وقت نمیشود مطمئن بود.
۴) داستان گنجور
برای سیستم بازبینی خروجیهای OCR گنجور، راهکارهای مختلفی میشد طراحی کرد: میشد با توجه به آن که من عدد اطمینان بازشناسی تکهشعرها را هم داخل پایگاه دادهها داشتم، اوّل آنهایی را که با دقت پایینتری خوانده شده بودند در معرض بازبینی بگذارم. میشد به ترتیب عمل کنم، یعنی دوستانی که بازبینی میکنند از اوّل شروع کنند و هر کسی که تازه میآید آخرین تکه شعری را که هنوز بازبینی نشده یا اگر همه حداقل یک دور بازبینی شدهاند، هنوز در دور دوم بازبینی نشده بازبینی کند و … .
اما خوب، من آسانترین -و البته از لحاظ پردازشی کمهزینهترین- راه را انتخاب کردم. هر بار بر اساس یک عدد تصادفی، یک خط شعر تصادفی در معرض بازبینی قرار میگرفت. مزیت این کار، نیاز به کمترین برنامهنویسی و همینطور به دلیل عدم نیاز به جستجو برای بازبینی نشده یا کمبازبینیشدهها سرعت و هزینهٔ پردازشی پایین بود.
اما در طولانی مدت چه اتفاقی میافتد؟ من حدود پنجاه هزار تکه تصویر بریده شده را در معرض بازبینی قرار داده بودم و اگر روزانه ۱۰۰۰ تکه از اینها بازبینی میشد باید در یک سیستم ترتیبی، همه در زمانی حدود دو ماه حداقل یک بار بازبینی شده باشند. اما در یک سیستم مبتنی بر اعداد تصادفی چه؟
نتیجه را احتمالاً میتوانید حدس بزنید. خیلی از روزها، بیش از ۱۰۰۰ تکه از شعرها بازبینی میشد (آمارش هنوز در این صفحه در دسترس است)، اما بعد از دو ماه چیزی حدود ۱۹۰۰۰ تکه بیش از یک بار و حدود ۲۶۰۰۰ تکه تنها یک بار بازبینی شده بودند و ۸۰۰۰ تکه هم اصلاً بازبینی نشده بودند (گزارش تا آن مرحله).
مطلوب آن بود که تمام تکهها، بیش از یک بار بازبینی شوند، برای کاهش تعداد بازبینینشدهها و یک بار بازبینیشدهها، کمی برنامه را دستکاری کردم: این بار کاربر از یک تکهٔ تصادفی شروع میکرد و بعد از آن به صورت ترتیبی بازبینینشدهها (در دو هفتهٔ اول) و فقط یک بار بازبینیشدهها (در ادامه) را بازبینی میکرد. گزارش نهایی کار را میتوانید اینجا بخوانید.
خلاصه آن که -با تشکر ویژه از تمامی دوستانی که در این کار مشارکت کردند- مرحلهٔ اول بازبینی خروجیهای OCR گنجور به ثمر نشسته است. برای برداشت محصول نهایی میتوانید سری به آثار بیدل و قاآنی در گنجور بزنید و اگر گنجور رومیزی دارید مجموعه اشعار متناظر را با شرحی که در این نوشته آمده به برنامه اضافه کنید.
و البته، یادتان باشد که این فقط مرحلهٔ اول بود و نهضت کماکان ادامه دارد.
لیستهای مرتب با اعداد فارسی
تگ ol (لیست مرتب) در html در CSS ویرایش ۲ توانایی نمایش اعداد به صورت فارسی را ندارد (از اعداد لاتین، رومی و ارمنی(!) پشتیبانی میکند اما اعداد را به صورت عربی یا فارسی نمیتواند نشان دهد). استایلهای انواع لیستها را در این استاندارد اینجا میتوانید ببینید. در استاندارد جدیدتر گویا قرار است پشتیبانی از شکل اعداد فارسی هم اضافه شود.
چند وقتی است استقبالهای شاعران را از هم (حافظ از سعدی، حافظ از سلمان، سلمان ساوجی از سعدی و …) را با توجه به میزان مشابهت کلمات ابیات و همینطور با توجه به وزن و قافیهٔ اشعار استخراج کردهام و در گنجور در دسترس قرار دادهام. دیروز به نظرم رسید بد نیست این فهرستها را با کمک تگ ol شمارهگذاری کنم. اما با توجه به نکتهای که در پاراگراف قبل گفتم امکان نمایش درست اعداد در متن فارسی وجود نداشت. جستجویی کردم و به این صفحه رسیدم. نویسندهٔ مطلب به کمک جاوا اسکریپت مشکل را حل کرده. با کمک اسکریپت او، اسکریپت سادهای نوشتم که امکان نمایش اعداد لیستهای مرتب را به صورت فارسی در اختیار میگذارد:
نوار لغزان با لغزندگی پایین
یکی از ایرادهای گزارش شده برای ویرایشهای قدیمیتر گنجور رومیزی این بود که نوارهای لغزان آن با کمک کلیدهای جهتی نمیلغزد. در واقع اگر ویرایش ۱.۶۳ و پایینتر آن را آزمایش بکنید میبینید که مثلاً نوار لغزان عمودی آن را، اگر کلید جهتی پایین را همینطور فشار دهید، بعد از سه چهار ثانیه بالاخره تسلیم میشود و راه میافتد اما خوب! سخت راه میافتد (دلیلش از لحاظ برنامهنویسی احتمالاً این است که کلید جهتی مزبور در واقع فوکوس را دارد بین کنترلها جابجا میکند و به هر کدام چند میلی ثانیه اجازهٔ مالکیت آن را میدهد تا آخر سر نوبت به نوار لغزان میرسد). توی ویرایش جدیدتر این مشکل را حل کردم.
اما «چطورش» شاید به درد برنامهنویسهای (احتمالاً تازهکار یا کمسواد مثل خودم) ویندوز فرمز بخورد (چون راه حلش را با جستجو پیدا نکردم): کنترل اصلی گنجور رومیزی یک User Control ساده است که نشانی شعرها یا دستههای شعرها و همینطور شماره بیتها با استفاده از کنترلهای LinkLabel و مصرعها با استفاده از یک کنترل مشتق از Label روی آن تعبیه شده و ویژگی AutoScroll آن فعال است. به این ترتیب، با توجه به جای پایینترین و سمت چپترین کنترل، نوارهای لغزندهٔ آن به طور خودکار ظاهر میشوند. من برای این که بتوانم کلیدهای جهتی را برای حرکت دادن نوارهای لغزان دریافت کنم رویداد PreviewKeyDown را برای این کنترل به صورت زیر نوشتم:
[code lang=”c#”]
private void GanjoorViewer_PreviewKeyDown(object sender, PreviewKeyDownEventArgs e)
{
bool isInputKey = true;
switch (e.KeyCode)
{
case Keys.Down:
if (VerticalScroll.Value + VerticalScroll.SmallChange <= VerticalScroll.Maximum)
VerticalScroll.Value += VerticalScroll.SmallChange;
break;
case Keys.Up:
if (VerticalScroll.Value - VerticalScroll.SmallChange >= VerticalScroll.Minimum)
VerticalScroll.Value -= VerticalScroll.SmallChange;
break;
case Keys.PageDown:
for(int i=0; i<2; i++)//!?
if (VerticalScroll.Value + VerticalScroll.LargeChange <= VerticalScroll.Maximum)
VerticalScroll.Value += VerticalScroll.LargeChange;
else
VerticalScroll.Value = VerticalScroll.Maximum;
break;
case Keys.PageUp:
for (int i = 0; i < 2; i++)//!?
if (VerticalScroll.Value - VerticalScroll.LargeChange >= VerticalScroll.Minimum)
VerticalScroll.Value -= VerticalScroll.LargeChange;
else
VerticalScroll.Value = VerticalScroll.Minimum;
break;
case Keys.Right:
if (HorizontalScroll.Value + HorizontalScroll.SmallChange <= HorizontalScroll.Maximum)
HorizontalScroll.Value += HorizontalScroll.SmallChange;
break;
case Keys.Left:
if (HorizontalScroll.Value - HorizontalScroll.SmallChange >= HorizontalScroll.Minimum)
HorizontalScroll.Value -= HorizontalScroll.SmallChange;
break;
default:
isInputKey = false;
break;
}
if (isInputKey)
e.IsInputKey = true;
}
[/code]
در مورد حلقهٔ دوتایی کلیدهای PageDown و PageUp، دلیلش را نمیدانم ولی بدون اصرار 😉 کار نمیکرد! بعد این رویداد را علاوه بر UserControl اصلی، همه جا، پس از ایجاد و اضافه کردن زیرکنترلهایش به آنها هم نسبت دادم:
[code lang=”c#”]
private void AssignPreviewKeyDownEventToControls()
{
foreach (Control ctl in this.Controls)
ctl.PreviewKeyDown += GanjoorViewer_PreviewKeyDown;
}
[/code]
در هر صورت، راه حل، کمی عجیب و غریب است ولی کار میکند. اگر دوستان راهحل بهتری سراغ دارند پیشنهاد دهند. کد گنجور رومیزی نیز در دسترس و قابل دریافت است (این صفحه را ببینید). فهرست تغییرات گنجور رومیزی را در این صفحه میتوانید ببینید.
گنجور رومیزی تحت لینوکس
چند روز پیش دوستی در مورد امکان ارائهی نسخهی مکینتاش گنجور رومیزی سؤال کرده بود.
میدانستم که به کمک پروژهی مونو میتوان برنامههای داتنتی را تحت لینوکس اجرا کرد. پیشتر هم به کمک ابزاری که از سوی توسعهدهندگان مونو ارائه شده (اینجا را ببینید)، سازگاری گنجور رومیزی را با مونو تحقیق کرده بودم. تنها ناسازگاری گزارش شده توسط این برنامه خاصیت راست به چپ نوار ابزار برنامه بود که در فهرست در دست اقدامهای پروژهی مونو قرار دارد.
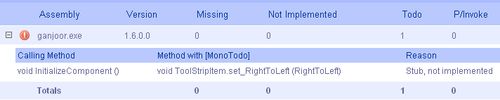
با توجه به آن که مونو نسخهی مکینتاش هم دارد دوستمان را به کد منبع گنجور رومیزی (قابل دریافت از اینجا) و پروژهی مونو ارجاع دادم و قرار شد اگر ایشان به نتیجه رسیدند مرا هم در جریان قرار دهند.
در هر صورت، امروز فرصتی شد تا به کمک دیسک زندهی مونو (قابل دریافت از اینجا) نظریهی امکان اجرای برنامه را تحت لینوکس آزمایش کنم.
نتیجه آن که با جایگزینی اسمبلی مربوط به ارتباط با پایگاه دادههای SQLite با نسخهی کاملاً Managed (من نسخهی جاری آن را از اینجا گرفتم) بدون نیاز به تغییر کد و در محیط مونو دِوِلپ میتوان پروژه را باز و کامپایل کرد (جالب آن که یک خط کد زاید را مونودولپ پیدا میکند و در موردش هشدار میدهد که فکر میکنم ویژوال استودیو در موردش هشدار نمیدهد) و نهایتاً آن را از طریق این محیط یا به کمک خط فرمان اجرا کرد.
ایراد قابل مشاهده (علاوه بر مشکل راست به چپ منو و نوار ابزار) نحوهی نمایش متون فارسی است که فکر میکنم اشکال از دیسک زندهی مونو باشد: با آن که امکان انتخاب زبان فارسی از منوی بوت دیسک زندهی یاد شده وجود دارد من نتوانستم در این محیط فارسی تایپ کنم و فکر میکنم بستههای زبان فارسی این دیسک ناقص هستند. به همین دلیل، حدس میزنم که تحت لینوکسی با پشتیبانی کافی از زبان فارسی بتوان برنامه را به صورت کم اشکال اجرا کرد.
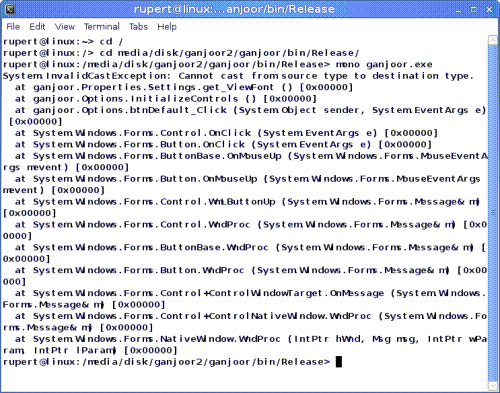
هر چند، پروژهی مونو هنوز گویا کار زیاد دارد. به عنوان نمونه، در صورتی که پنجرهی «تنظیمات» گنجور رومیزی را باز کنید و روی دکمهی «تنظیمات پیشفرض» کلیک کنید، برنامه بلافاصله بسته میشود و در ترمینال چنین خطایی اعلام میشود:
با این وصف، احتمالاً میتوان به زودی مستقل بودن از سیستم عامل را به ویژگیهای برنامههای داتنتی اضافه کرد که پیش از این از جمله خاصیتهای منحصر به فرد برنامههای مبتنی بر جاوا بوده (و البته به دلیل نقائصش یا احتمالاً به دلیل حسادت برنامهنویسان سایر سکوها برایش جُکهایی مثل این ساختهاند: جاوا: یک بار بنویسید، همه جا اشکالش را بیابید!، یا این یکی).
پینوشت: با لینوکس OpenSUSE نگارش ۱۱.۱ به صورت نصب کامل (که امکان تایپ عربی داشت) هم امتحان کردم. نتیجه همینی است که در تصاویر مشخص است. ضمن آن که برای اجرای برنامهی داتنتی تحت مونو نیازی به کامپایل مجدد آن نیست و من بدون کامپایل مجدد و با استفاده از فایل اجرایی تولید شده توسط ویژوال استودیو، پس از جایگزینی اسمبلی مربوط به SQLite توانستم برنامه را به کمک فرمان mono اجرا کنم.
پینوشت ۲: نرمافزار ساغر راه حل نهایی برای مرور اشعار گنجور تحت لینوکس است. اینجا را ببینید.
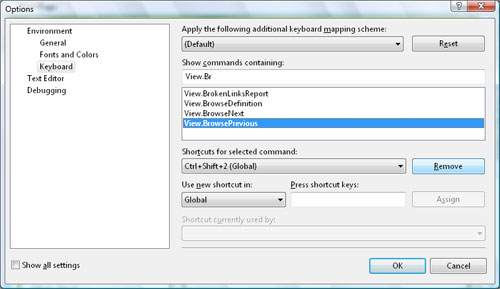
میانبر مزاحم
اگر مثل من با Ctrl+Shift+2 نیمفاصله میزنید، با ویژوال استودیو کار دارید و نهایتاً باید هر از چند گاه در محیط این نرمافزار فارسی تایپ کنید احتمالاً متوجه شدهاید که تایپ نیمفاصله در محیط این نرمافزار در حالت پیشفرض ممکن نیست (من تا به حال با کپی مشکل را حل میکردم!). علت هم مشخص است: این کلید ترکیبی با یکی از میانبرهای ویژوال استودیو تداخل میکند. چند روز پیش یکی از همکاران میانبر متداخل 😉 را پیدا کرد (View.BrowsePrevious). برای حل مشکل از طریق پنجرهی Options این نرمافزار آن را غیرفعال کنید یا تغییر دهید (تصویر را ببینید).
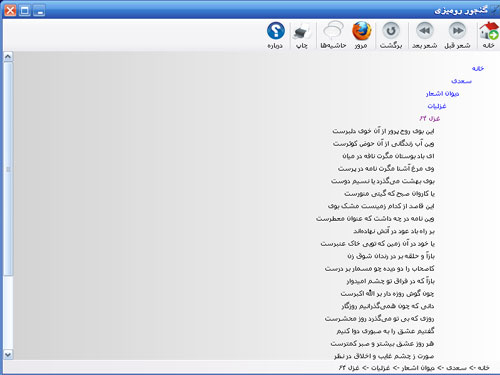
رومیزی نو
کمی روی گنجور رومیزی کار کردم. حالا بالایش یک نوار ابزار دارد با چند دکمه، پایینش یک نوار وضعیت و خوب! یک کارهایی هم میکند 😉 . برایش یک نصاب ساختم و پروژه را به سایت سورس فورج منتقل کردم. تصویری از آن را ببینید:
دوستانی که آن فایل ۲۱ مگابایتی پیشین را دریافت کردهاند کافی است فقط این فایل اجرایی را دریافت کنند و آن را در پوشهای که برنامه را در آن باز کردهاند جایگزین فایل قبلی کنند. باقی دوستان، در صورت تمایل برنامه را از اینجا دریافت کنند.